什么是RAG和向量数据库
概述
- RAG:结合「检索」与「生成」的混合式架构,通过从外部文档库中检索相关信息,再由大模型生成最终答案,兼具可靠性与创造力。
- 向量模型:将文本、图像等非结构化数据映射到高维向量空间,以便计算相似度。
- 向量数据库:专门存储和检索这些高维向量,支持海量数据的高效近似最近邻搜索(ANN)。
整体流程示意:
用户提问
↓
┌────────────┐ ┌───────────────┐ ┌────────────────┐
│ 1. Embedding │ → │ 2. 向量检索 │ → │ 3. 内容拼接 │
│ 文本向量化 │ │ (Vector DB) │ │ + Prompt │
└────────────┘ └───────────────┘ └────────────────┘
↓
┌────────────────────────┐
│ 4. 大模型生成回答 │
└────────────────────────┘
RAG 原理
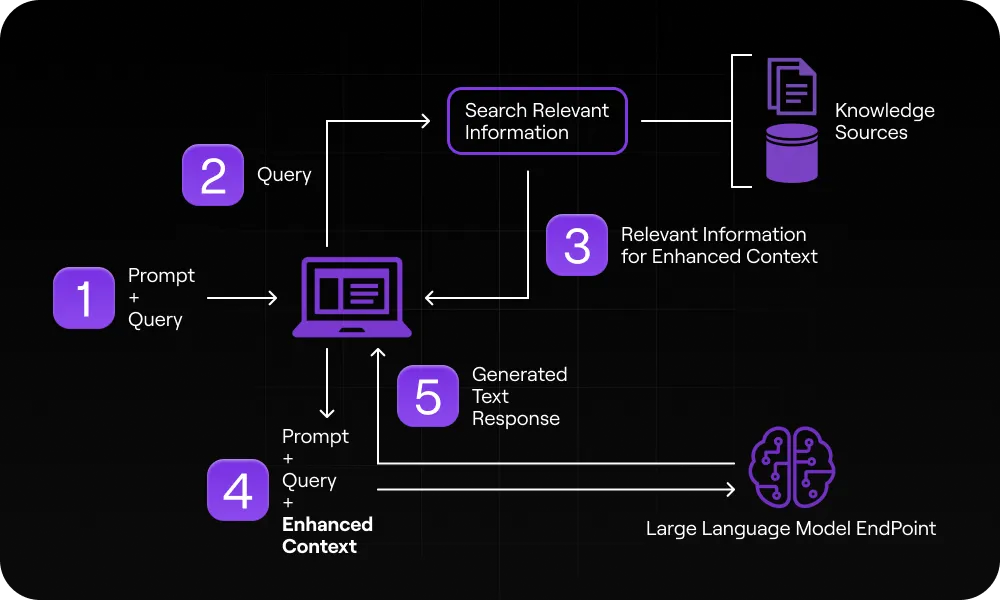
RAG(Retrieval-Augmented Generation)是一种结合检索和生成的技术,用于增强大型语言模型(LLM)的回答能力。与传统只依赖模型训练数据不同,RAG允许模型在生成回答时动态检索外部知识库的信息,好比让 AI 进行“开卷考试”。具体来说,RAG 系统通常包括以下步骤:
- 数据摄取(Ingestion):将权威信息(如公司文档、数据库等)加载到向量数据库或检索系统中;
- 检索(Retrieval):当用户提出问题时,系统将问题转化为向量,并在知识库中搜索语义最相近的内容;
- 上下文融合(Augmentation):将检索到的相关信息与用户问题合并,构造新的提示(prompt)给模型;
- 生成(Generation):将增强后的提示输入LLM,由模型根据这些上下文生成回答。
通过上述流程,RAG 可以让模型在回答问题时参考实时的、特定领域的知识,从而提高准确性和相关性。例如,我们可以把 RAG 系统比作一个学生做“开卷考试”,学生(LLM)一边答题,一边翻阅教科书(向量数据库中的文档)来查找答案。在这个过程中,向量模型和向量数据库发挥关键作用:前者将查询和文档转换为数字向量,后者根据向量相似度快速检索相关内容。
示意图:
Query 向量: [0.12, -0.07, ...]
┌───────────────────────────────────┐
│ Vector DB │
│ ┌───────┐ ┌───────┐ ┌───────┐ │
│ │ 文档1 │ │ 文档2 │ │ 文档3 │ ... │
│ │ [0.10,…]││[-0.05,…]││[0.15,…]│ │
│ └───────┘ └───────┘ └───────┘ │
└───────────────────────────────────┘
相似度排序 → Top-k 文档
向量模型(Embedding 模型)
向量模型(或嵌入模型)是将文本、图像等数据映射为高维向量表示的 AI 模型。可以把这些向量看作数据的“数字指纹”或语义地图上的坐标。
向量表示
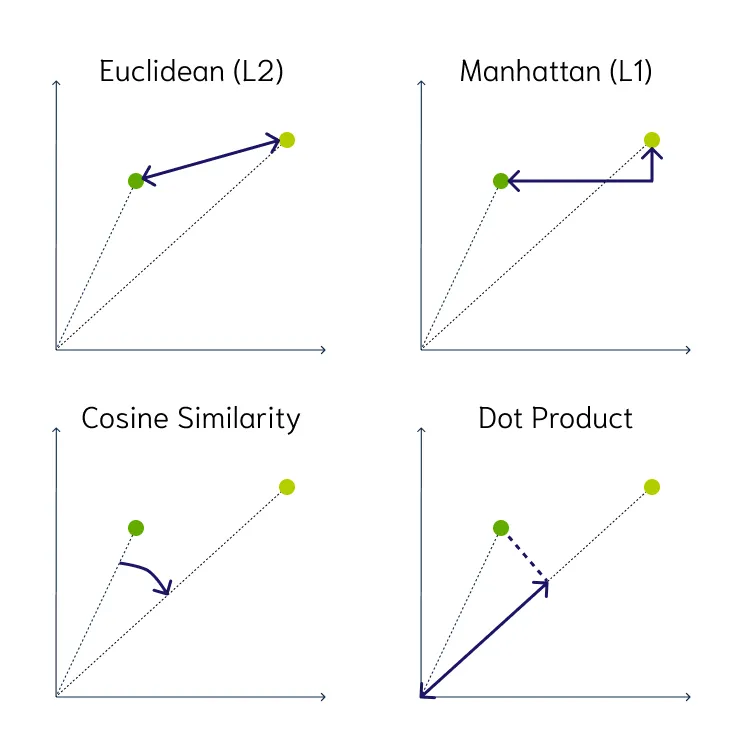
- 概念:将文本、图片、音频等映射为固定维度的实数向量,向量间的距离/夹角反映语义相似度。
- 度量:常用余弦相似度(Cosine Similarity)、欧氏距离(Euclidean Distance)等。
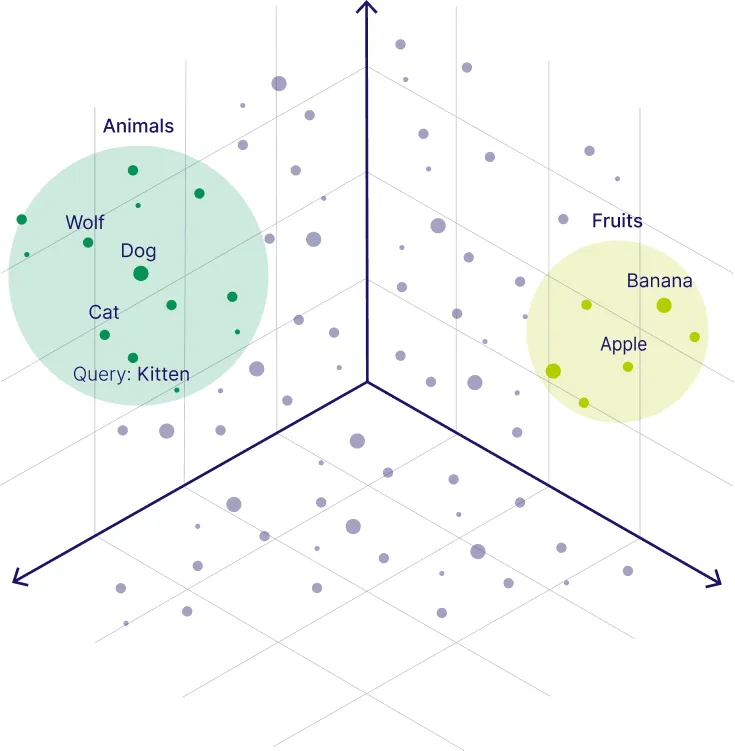
在这种表示下,语义相近的内容会在向量空间中聚集(距离更近)。例如,“猫”“狗”等词的向量在空间中会聚在一起,因为它们都是“动物”相关词;而与车辆相关的词则聚成另一簇。
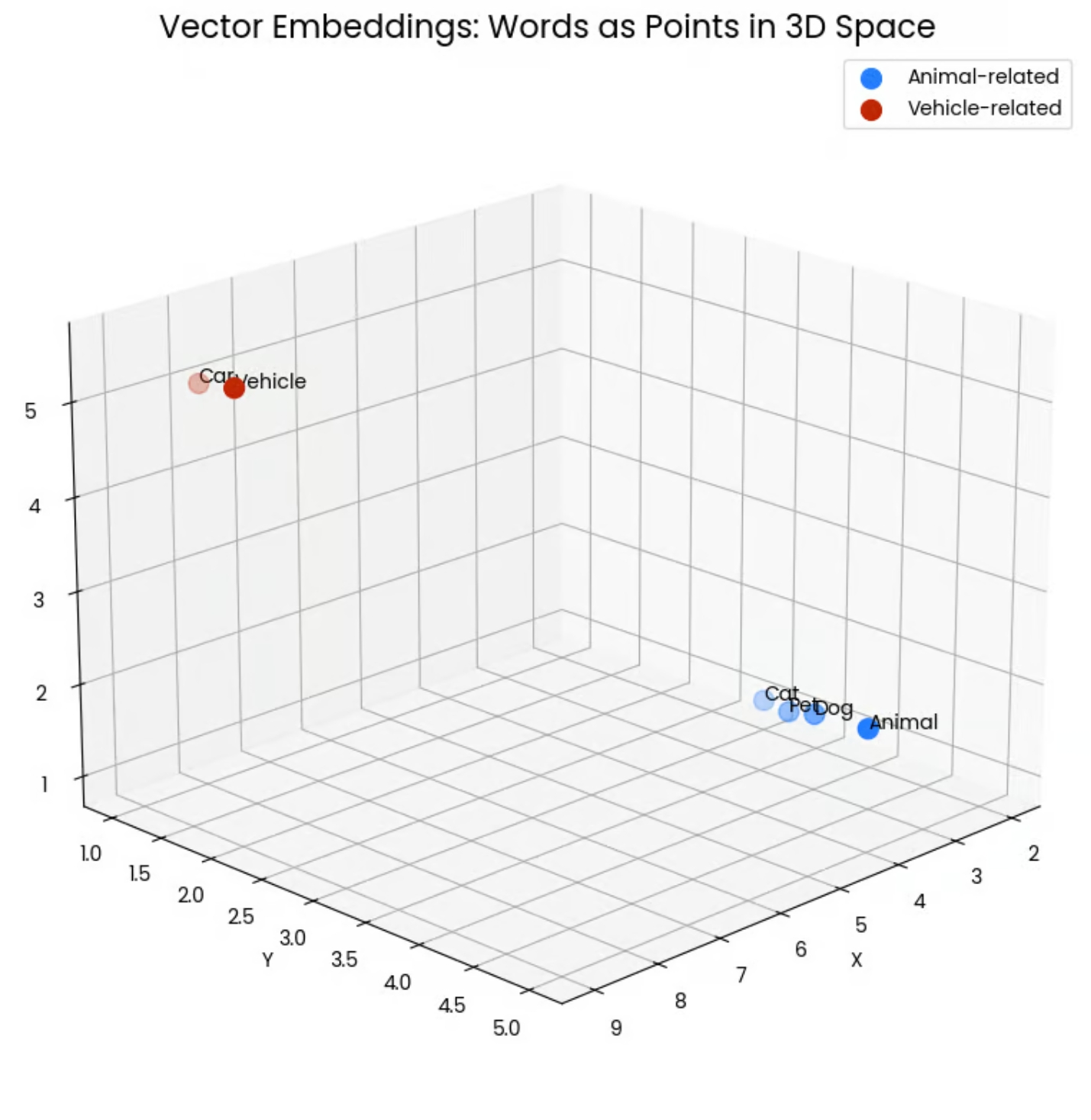
通过向量表示,模型可以量化语义相似度——两个内容的向量越接近,它们的含义就越相近。
度量:常用余弦相似度(Cosine Similarity)、欧氏距离(Euclidean Distance)
常用的向量模型包括 OpenAI 的文本嵌入模型、Sentence-BERT 及各种预训练语言模型的嵌入层等,它们能将句子或段落转换为数百至上千维的向量。向量模型使得复杂的语义信息能被机器理解和计算,为后续的相似度检索打下基础。
向量数据库(Vector Database)
向量数据库是一种专门用于存储和检索向量的数据库。它索引、存储带有向量表示(嵌入向量)的数据对象(如文本段、文档片段、图像等),并提供高效的相似度搜索。查询时,系统将用户输入转为向量,与数据库中所有向量进行比对,快速返回那些在语义上最相似的条目(向量距离最近者)。可以把向量数据库想象成一个按内容相似性排序的图书馆索引:当你有查询时,就像给馆员一个关键词(向量),图书馆(向量数据库)会在语义上最相关的书籍(数据项)中帮你找答案。
主流向量数据库对比
目前常用的向量数据库及其特点包括:
-
FAISS:Meta(Facebook)开源的向量检索库。它专注于近似最近邻搜索,支持多种索引算法,非常适合对性能要求极高的场景(如需要在数千万甚至上亿条向量中快速检索),并且支持 GPU 加速。但作为库使用,需要自行管理资源和部署。
-
Pinecone:商业化的全托管向量数据库。它提供高可靠性、弹性伸缩的向量搜索服务,用户无需部署和维护基础设施。Pinecone 支持混合搜索(向量+关键词)、实时数据写入和大型向量集查询,适合企业级应用,但使用成本相对较高。
-
Weaviate:开源的向量数据库。它除了向量搜索外,还支持基于 GraphQL 的灵活查询和知识图谱关系,可处理多模态数据。Weaviate 易于扩展,提供丰富的内置模块(如 OpenAI 嵌入模块等),适用于需要结构化语义关联的场景。
-
其他:例如 Milvus(开源,擅长大规模向量集;GPU 优化)、ChromaDB(轻量级,易于本地开发)、Qdrant(Rust 实现,强大的元数据过滤)等也很流行。总体而言,选型时可根据场景需求——规模、检索性能、部署复杂度和成本等因素进行权衡。例如,研究原型或小规模项目可选择 Chroma、FAISS 等开源方案;而对 SLA 要求高、数据量大的企业应用往往会采用 Pinecone、Weaviate 等托管/成熟解决方案。
RAG 工作流程示意图
系统首先将原始文档或数据拆分并嵌入向量数据库,然后接收用户查询,将其转换为向量并检索相关文档片段,最后将检索到的信息与原始问题一同输入 LLM,生成最终回答。通过这种方式,生成模型不仅依赖自身“记忆”,还能实时参考外部知识,从而获得更准确、更可信的答案。
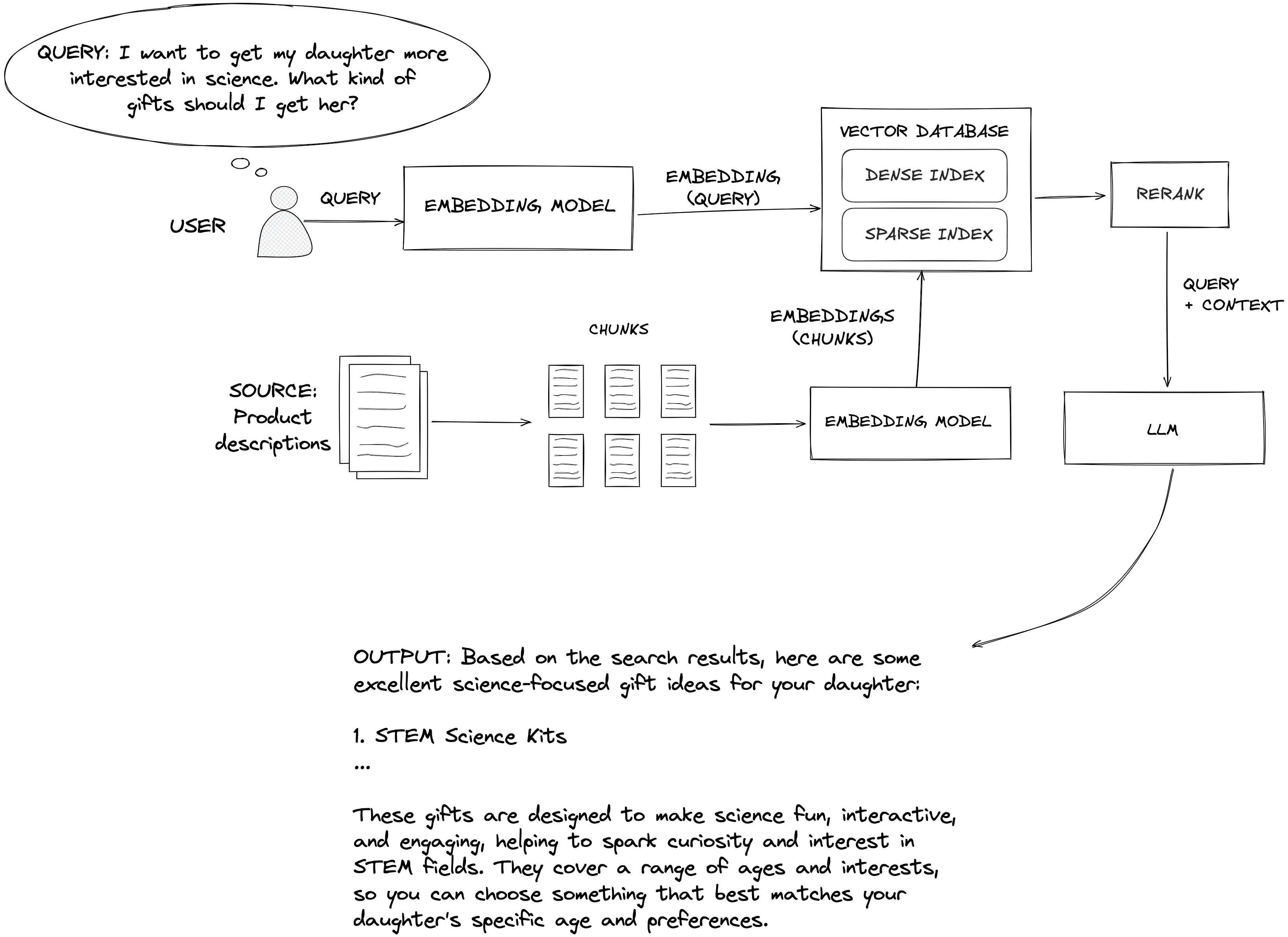
用户问题经过嵌入检索模块,从向量数据库中获取相关内容,然后与问题一同传递给生成模型(LLM),得到最终回答。图中展示了文档拆分、向量化、检索、重排序等步骤
代码示例
下面用 Python 演示一个简单的 RAG 应用示例(采用 LangChain 库)。该示例首先将文本数据转换为向量并存入 FAISS 向量数据库,然后利用 RetrievalQA 组件执行检索问答。具体代码如下:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 示例文档数据
docs = [
"这是文档1的内容,包含一些信息。",
"这是文档2的内容,包含其他信息。",
# 可以继续添加更多文档...
]
# 生成文档嵌入并创建向量数据库
embeddings = OpenAIEmbeddings() # 使用 OpenAI 生成文本嵌入
vector_store = FAISS.from_texts(docs, embeddings) # 创建 FAISS 向量数据库并插入文档
# 构建基于检索的问答链
llm = OpenAI() # 调用 OpenAI 生成式模型
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=vector_store.as_retriever())
# 执行问答
query = "文档1里提到了什么信息?"
answer = qa_chain.run(query)
print(answer)
以上代码中,我们先通过 OpenAIEmbeddings 将文档编码为向量,并通过 FAISS.from_texts 存入向量库。然后使用 RetrievalQA 定义问答链:系统会自动检索相关文档片段并将其传递给 LLM 最终生成答案。LangChain 官方文档也提供了类似的 RAG 实现示例。
应用案例
RAG 在实际产品中的应用非常广泛。常见场景包括:
-
文档问答系统/企业知识库助手:用户可以针对公司内部文档、手册或知识库进行查询,RAG 系统会实时检索相关内容并生成答案。例如,员工用自然语言问问题,系统从内部文档中找到相关段落并总结回答,提高了信息获取效率。
-
智能客服机器人:RAG 能使客服机器人根据最新的用户数据和产品文档提供准确回答,而不只是死记预设答案。无论是计费问题、产品功能,还是故障排查,机器人都能基于最相关的实时信息给出个性化的回复,提升客户体验。
-
其他行业助手:在医疗、金融等领域,RAG 也被用来构建智能助手。例如,医疗咨询机器人可以结合医院内部的指南与最新研究,给病人或医生提供实时、权威的解答;金融分析系统可以根据历史报告和实时数据生成针对性分析和预测。总之,任何需要领域知识检索+自然语言回答的场景,都适合采用 RAG 架构。
通过上述组件的结合,RAG 架构能够让AI产品在知识问答、智能助手、客服机器人等场景中表现出更强的实时性、准确性和可控性,使产品产生更符合业务需求、可信赖的输出