数据中台它是什么
到目前为止已经拥有的实战项目:
-
大麦: 高并发业务项目,验证了极限场景下的稳定性
-
大麦AI: 集成热门大模型的智能体,体现了智能化能力
-
link-flow: 支持流量切换与无损发布的工程化组件
这些项目覆盖面广、含金量高,但我还是想推出新的项目帮助大家更好的学习,还有什么好的方向吗?
其实现在市场上的大多数业务依然是“用户操作 → 执行业务 → 返回结果”的线性流程(如外卖、点评、后台管理、打车等)。这类项目看多了容易审美疲劳,面试官也见怪不怪。要想真正 “亮眼”,需要跳出线性业务的范式。
数据中台来了
数据中台 并非另一种“增删改查”,而是一个面向数据生产、治理、资产化与服务化的系统工程。它连接业务、算法与运营,支撑多业务、多场景的非线性数据流转与复用。
项目背景
无论短视频、在线教育还是内容社区,都会遇到相同痛点:观看量怎么算?完播怎么算?喜欢率、不喜欢率、完播率怎么定义才统一?怎么按天、周、月、年稳定地给到业务?
如何把“口径变更、维度扩展、数据源调整、实时诉求”压缩到工程可控的范围?本项目正是为解决这些共性难题而生。
项目诞生原因
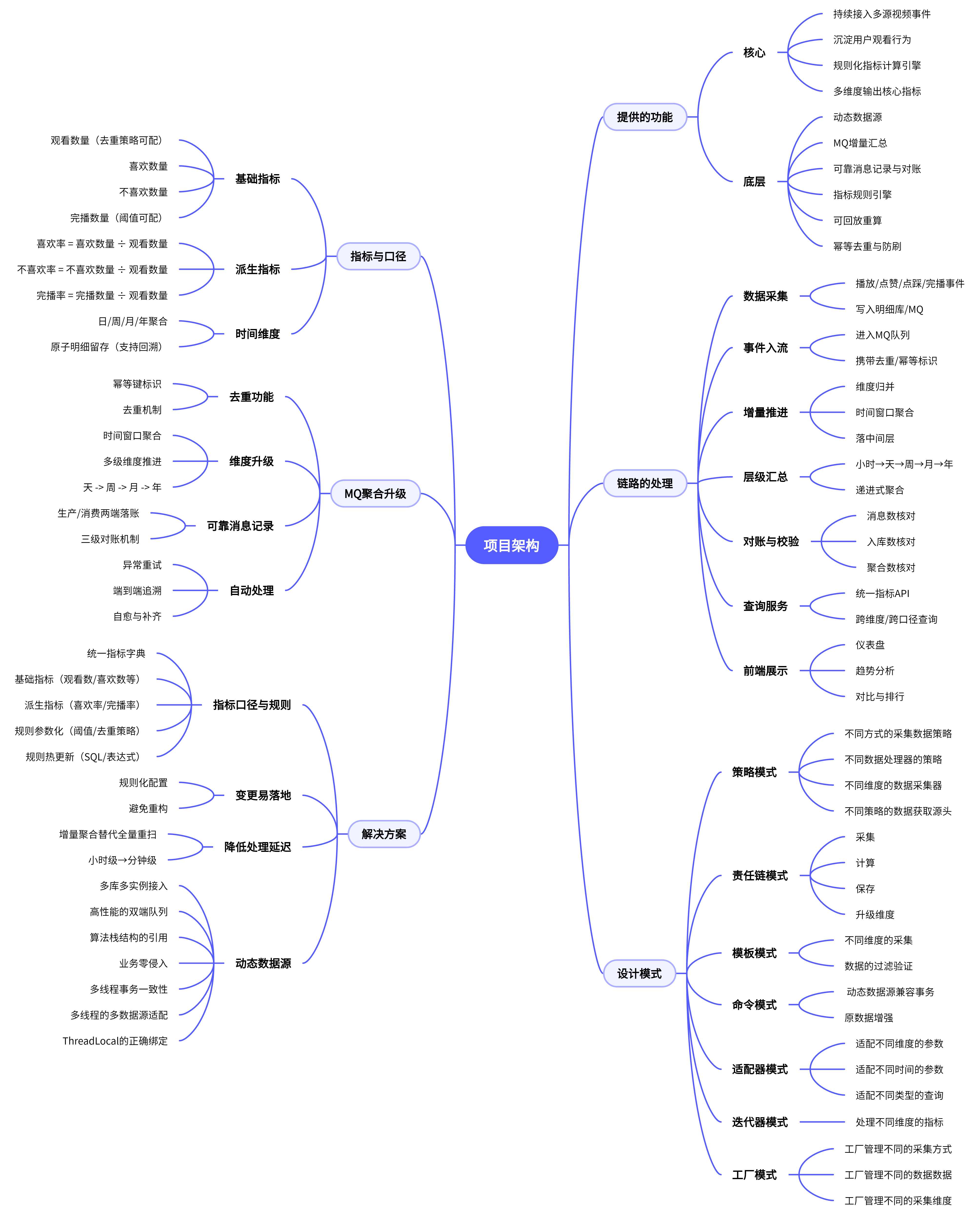
这是一个 “视频指标业务中台”。持续接入多源视频播放与互动事件,沉淀用户观看行为(时长、点赞/不喜欢、是否完播),通过规则化的指标计算引擎,按天、周、月、年等多维口径输出核心指标:观看数量、喜欢数量、不喜欢数量、完播数量、喜欢率、不喜欢率、完播率。
又内置了大量可被深挖的底层能力(动态数据源、基于 MQ 的增量汇总、可靠消息记录、消息记录的对账、指标规则引擎、可回放重算、幂等去重与防刷等),非常适合作为 “面试可讲、生产可用” 的代表项目。
一句话:让指标“准、快、稳、易改、可追溯”。
处理链路(高层视角)
- 数据采集 → 播放、点赞、点踩、完播事件写入明细库、MQ
- 事件入流 → 进入 MQ,携带去重/幂等标识
- 增量推进 → 消费端进行维度归并与时间窗口聚合,落中间层
- 层级汇总 → 小时→天→周→月→年依次推进
- 对账与校验 → 消息数、入库数、聚合数三级核对
- 查询服务 → 统一指标 API,跨维度/跨口径查询
- 前端展示 → 仪表盘、趋势、对比与排行
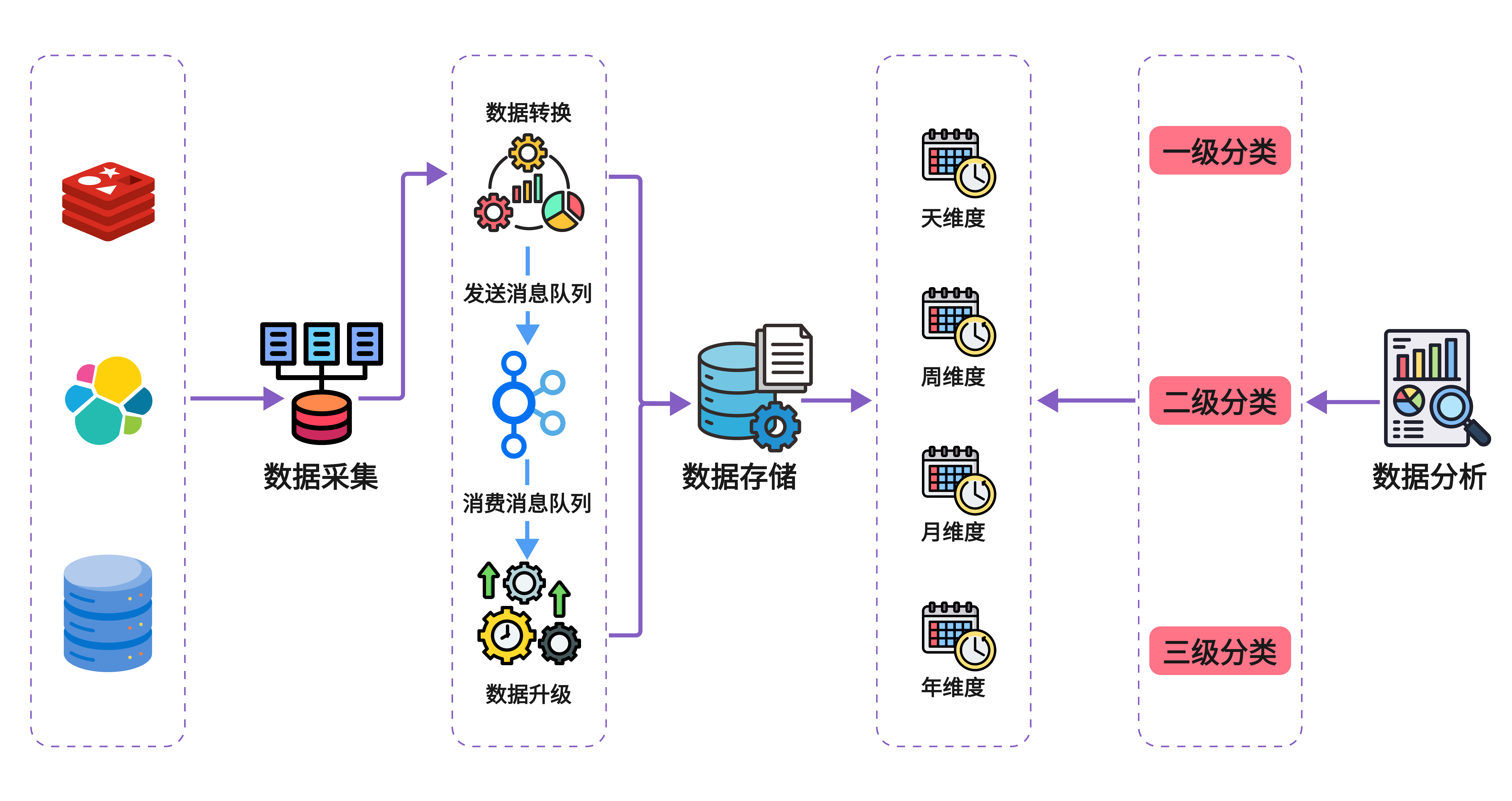
如果没有数据中台,会有哪些问题
- 口径冲突: A 报表与 B 报表“观看量”对不上,扯皮时间远超修复时间
- 时效性与成本的拉扯: 纯离线批处理延迟高(小时/T+1),全量重算贵且易扰动生产库
- 改动成本高: 每次加/改指标都要穿透多服务、多 SQL、多定时任务,牵一发动全身
- 需求变化频繁: 新增/改口径/加维度是常态,用“改代码+发版”应对,交付慢且风险高
- 消息无保障: 丢消息/重复消费导致数据偏差,且缺少可回放手段
- 多源接入脆弱: 临时切库/迁移/扩容风险高,切换不可控
- 无法定位问题: 错数/丢数查因困难,指标变更不可追,错了也说不清为啥错
中台化将这些 “共性难题” 平台化沉淀,形成可复用、可演进、可观测的能力底座,让各业务线 “拿来即用”
解决了什么问题(可以深挖的点)
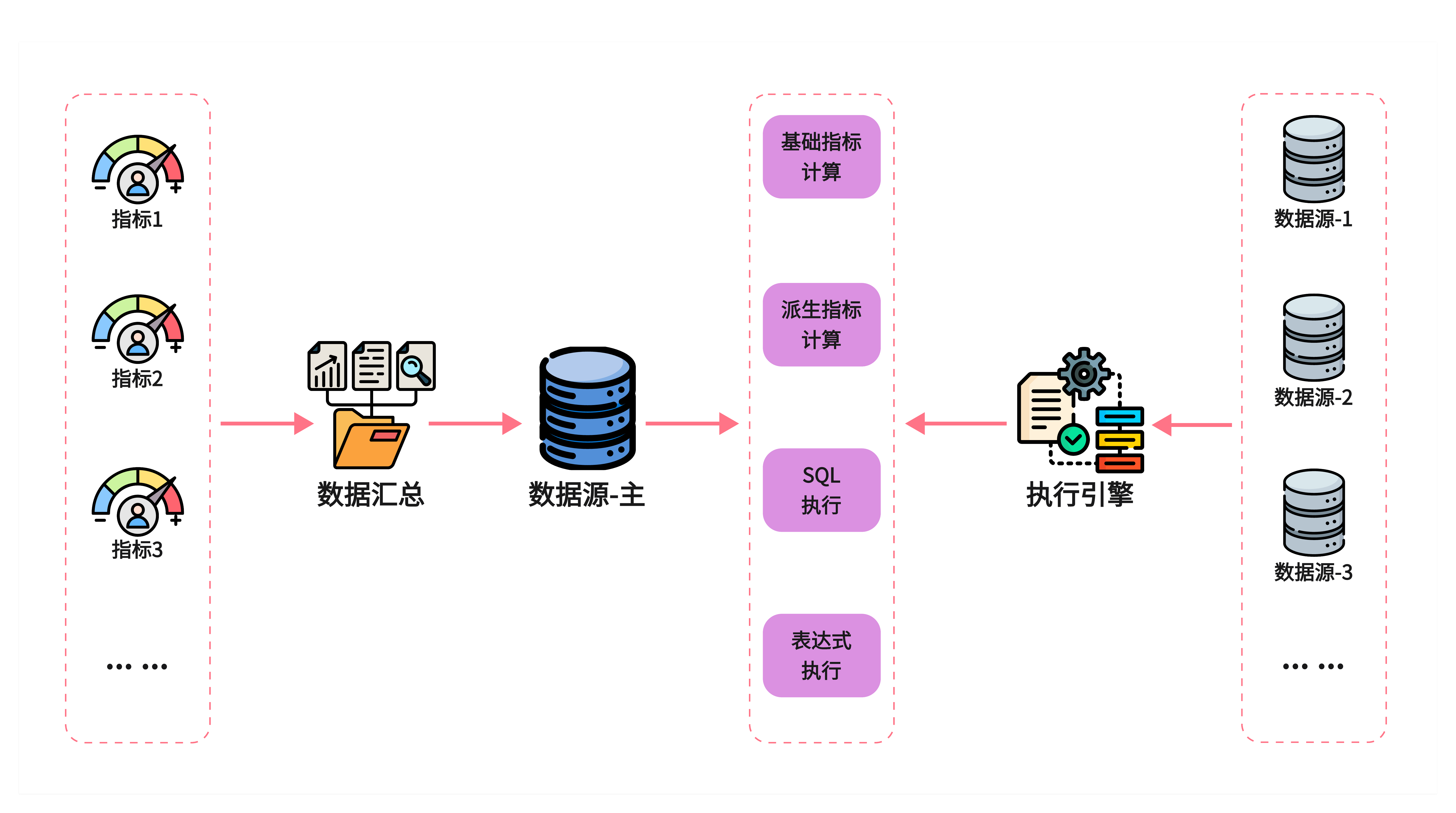
指标口径与规则
- 统一指标: 同一指标进行统一口径字典+规则引擎
- 基础指标: 观看数、喜欢数、不喜欢数、完播数
- 派生指标: 喜欢率、不喜欢率、完播率
- 规则参数化: 阈值(如 95% 完播)、去重策略、防刷规则、过滤条件
- 灵活执行: 支持 SQL/表达式两种形态,规则热更新
变更易落地
指标口径规则化,支持热更新;“加一个新指标/改口径”不必重构
减少 T+1 延迟
增量聚合替代全量重扫,把小时级/天级延迟压到分钟级/小时内
动态数据源
- 多库接入: 多库多实例接入,新增或减少数据源都可以实现业务零侵入
- 多线程: 在多线程或者线程池下实现多数据源的事务一致性
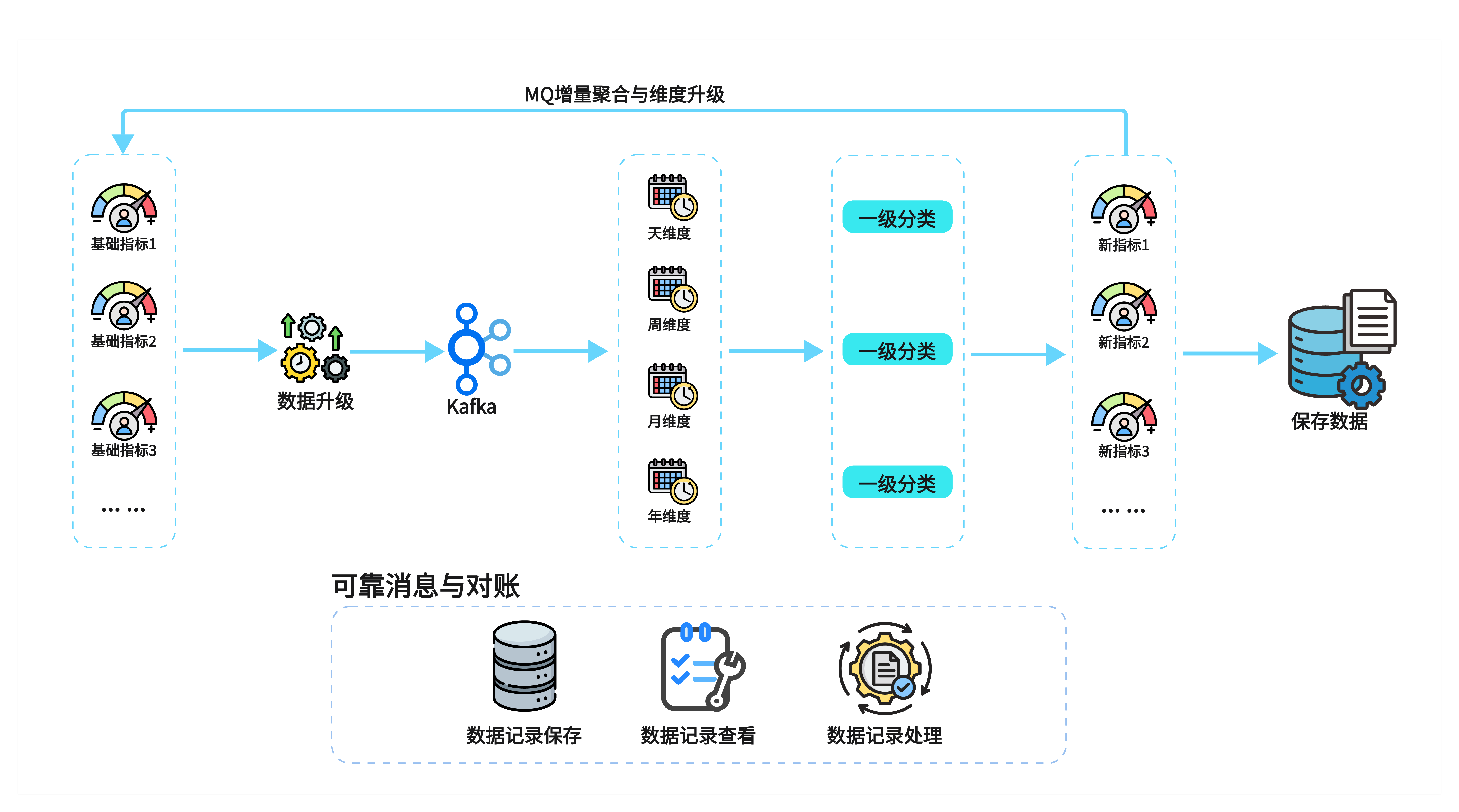
MQ 聚合升级与可靠消息记录
- 去重功能: 行为事件入流,携带幂等键与去重标识
- 维度升级: 消费端进行时间窗口聚合与多级维度推进(小时→天→周→月→年)
- 记录保存: 生产/消费两端落账,对账“消息数→入库数→聚合数”
- 自动处理: 异常重试、端到端可追溯,错了能自愈、能补齐,形成可追溯闭环
指标与口径
基础指标
- 观看数量: 有效播放事件次数(去重/防刷策略可配置)
- 喜欢数量: 点赞事件次数
- 不喜欢数量: 点踩事件次数
- 完播数量: 播放至阈值(如 95% 或 100%)的次数(阈值可配置)
派生指标
- 喜欢率 = 喜欢数量 ÷ 观看数量
- 不喜欢率 = 不喜欢数量 ÷ 观看数量
- 完播率 = 完播数量 ÷ 观看数量
时间维度
按天/周/月/年 聚合;同时保留原子明细以支持回溯与重算
业务维度
- 一级维度: 视频类型的总分类,如:评测类、科普类、解说类
- 二级维度: 视频的细分类,如:评测类下:数码产品、汽车、家居产品
- 三级维度: 视频本身的内容 视频 id、内容、时长等
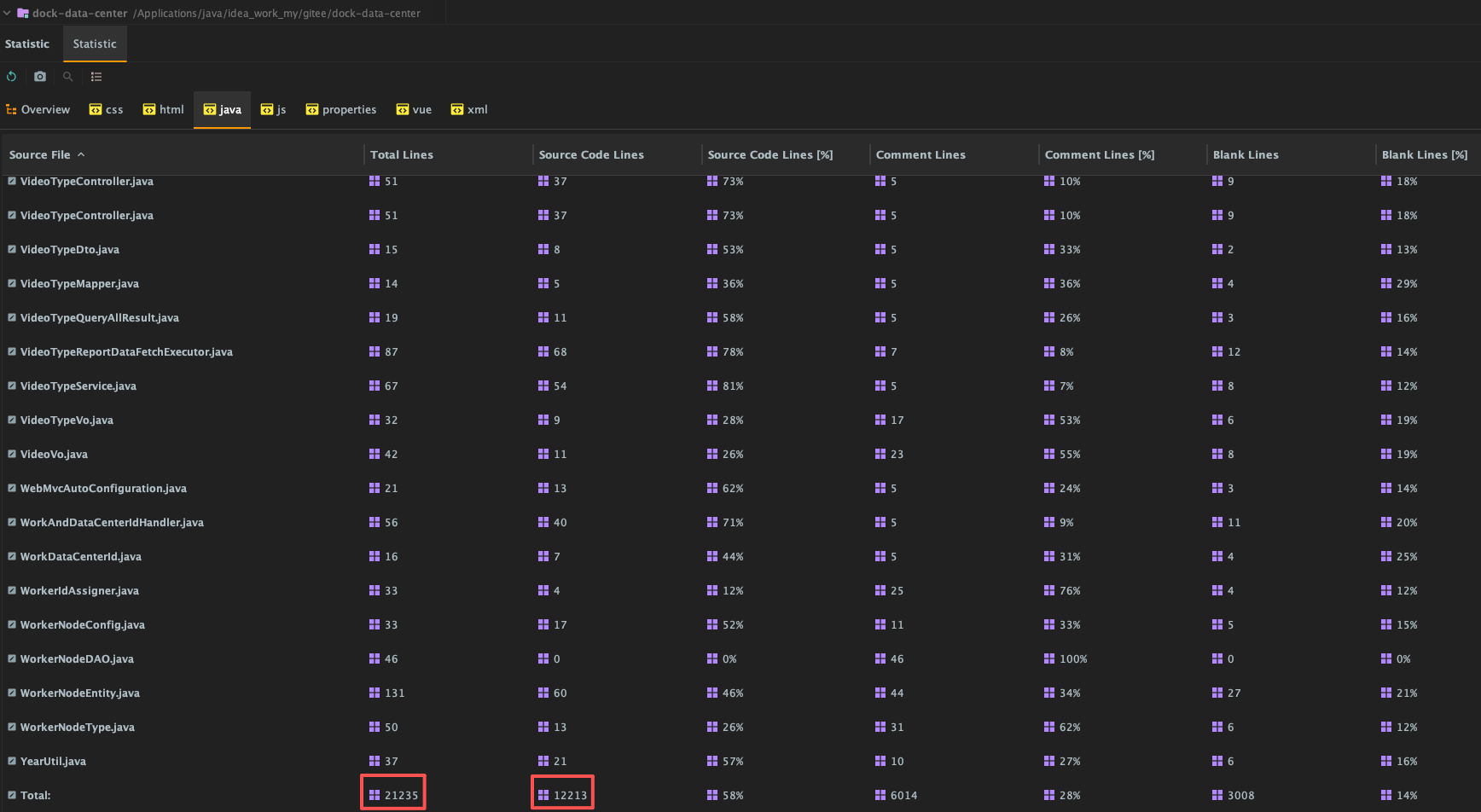
代码数量
- 后端代码包含了注释和本身代码: 2.1万行 行左右
- 后端代码仅包含本身代码(不包含注释): 1.2万行 行左右
只通过本身代码量(不包含注释)就可以看出,数据中台项目的复杂度和完整度都非常高,足以支撑起一个真实的生产环境
而包含了注释的代码量将近 翻了一倍 的量,足以看出项目对内容的详细讲解是非常完善的
代码的亮点
项目中的代码设计亮点非常的多,设计模式都只算是基操了,更多的是在实际业务中对各种复杂场景的处理,简单介绍几个功能亮点:
处理规则业务逻辑的统一
通过对功能的抽象设计,和明确的层级划分,将采集功能和查询功能进行了统一的适配,后续再扩展新功能,只需要实现对应的处理器即可,符合开闭原则
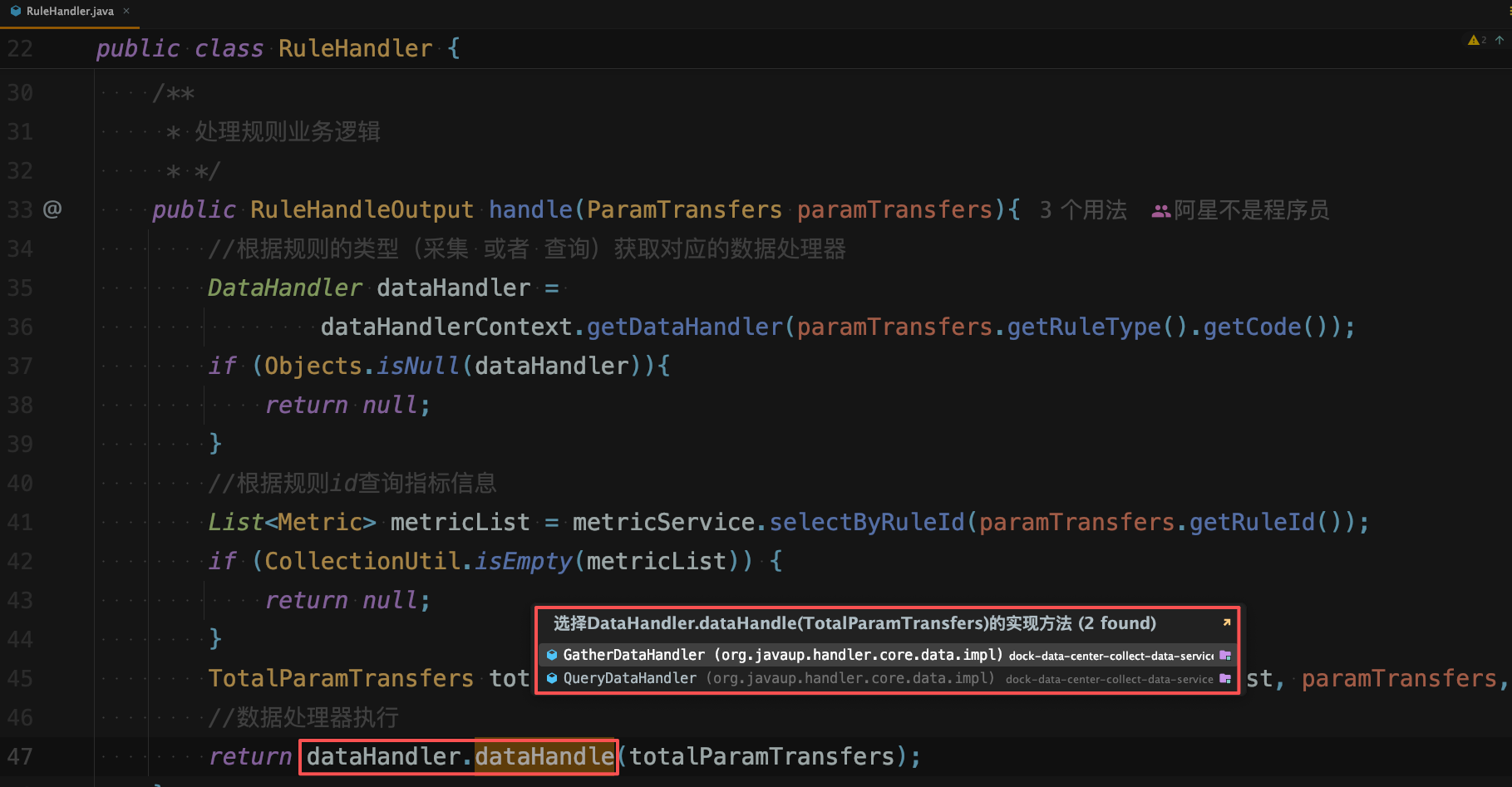
责任链的执行
在处理数据的过程时,包括:采集、计算、保存、升级维度 这几个过程。
通过责任链模式,将各个处理器串联起来,形成一个完整的处理流程,符合单一职责原则
public abstract class AbstractDataChainHandler {
/**
* 责任链中的下一个元素
*/
protected AbstractDataChainHandler nextAbstractDataChainHandler;
public AbstractDataChainHandler setNextChain(AbstractDataChainHandler nextAbstractDataChainHandler) {
this.nextAbstractDataChainHandler = nextAbstractDataChainHandler;
return nextAbstractDataChainHandler;
}
/**
* 责任链处理逻辑
* @param totalParamTransfers 总参数传输对象
*/
public void executeChain(TotalParamTransfers totalParamTransfers) {
handler(totalParamTransfers);
if (Objects.nonNull(nextAbstractDataChainHandler)) {
nextAbstractDataChainHandler.executeChain(totalParamTransfers);
}
}
/**
* 执行业务逻辑
* @param totalParamTransfers 总参数传输对象
*/
protected abstract void handler(TotalParamTransfers totalParamTransfers);
/**
* 执行顺序
* @return 执行顺序
*/
protected abstract Integer order();
}
其他的亮点
先简单介绍了两个小亮点,关于其他质量高的功能还有很多很多,这里就不一一列举了,更多的内容可以在项目讲解中慢慢的体会
项目架构
适合哪些人群学习?
- 已经学习过 SpringBoot、Redis、MySQL、MQ 消息队列 等技术的小伙伴
- 不想再学习 瑞吉外卖、黑马点评 这种已经烂大街的业务,想要学习 完全新的,能让人眼前一亮 的业务
- 希望进一步提升技术能力,例如:SpringBoot 自动状态化配置、动态数据源、多线程事务一致性、设计模式、架构思维下的业务扩展 等
- 想要在面试中拥有 独特竞争力,并能在众多候选人中 快速脱颖而出 的同学
面试场景:高频追问与答法思路
1)为什么选 MQ 增量而不是纯 SQL 批处理?
- 作答要点
- 批处理延迟高、峰值资源抖动大、全量重扫成本高
- MQ 事件流 + 窗口聚合降低时延与成本,并天然支持回放与补算
- 可落地细节
- 指标延迟: 小时级/T+1 → 分钟级/小时内
- 成本: 存算分离 + 增量写,避免日级全表 Scan
2)消息如何“不丢不重”?幂等怎么做?
- 作答要点
- 组件化: 幂等键(业务主键/消息id)+ 幂等注解 + 幂等功能的组件
- 可落地细节
- 对账: 生产数=入库数=聚合数;差异阈值报警;缺口回放
- 幂等键示例:
@RepeatExecuteLimit(name = CONSUMER_UP_DIMENSION_MESSAGE,keys = {"#upgradeDimensionMessage.messageId"})
3)至少一次/至多一次/恰好一次如何取舍?
- 作答要点
- 业务优先“最终一致”与可回溯,“至少一次 + 幂等”更稳健
- 可落地细节
- Kafka + 幂等功能 + 消息记录验证 + 消息记录保存 + 事务
4)计算引擎与 SQL 并存如何权衡?
- 作答要点
- 基础指标走 SQL,派生指标/频变更走表达式
- 规则热更新、指标可配置化
- 可落地细节
- 基础指标、派生指标的灵活管理
- 规则的在线更新
5)如何做对账?对哪些环节对?
- 作答要点
- 三段对账: 涉及到的维度 → 消息数 → 明细入库数 → 入库的维度
- 差异阈值报警 + 自动补偿/回放
- 可落地细节
- 指标: 对账通过率、缺口率、补偿成功率、闭合时延
- 可追溯: 消息链路id
6)数据模型与分层怎么设计?
- 作答要点
- TotalParamTransfers(总参数)、Handler(不同的处理器)、Context(策略上下文)、RuleHandleOutput(结果输出)
- 可落地细节
- 参数分层: ParamTransfers、TotalParamTransfers 设置不同层级的参数传递
- 处理器分层: Handler 抽象类定义不同的处理器,例如:采集处理器,查询处理器
- 策略上下文: Context 类用于封装同一功能下的不同策略上下文信息
- 结果输出: RuleHandleOutput 类用于封装执行的输出结果
8)成本与容量如何规划?如何压测?
- 作答要点
- 量化: QPS、事件大小、峰谷比、窗口宽度、保留期
- 压测: 生产级回放/录制;限流与背压策略预设
- 可落地细节
- 峰值 10x 保护;Topic 分区/消费者并行度调参公式化
- 存储预算: 热存 N 天,冷存 M 月;
9)降级与兜底方案有哪些?
- 缓存兜底(近似指标)、延迟扩容
- 非关键指标关闭、窗口放宽、低优先队列延后处理