NIO和Netty总结_1
nio重要的概念
Selector 选择器
public abstract class Selector implements Closeable {
......
/**
* 得到一个选择器对象
*/
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
......
/**
* 返回所有发生事件的 Channel 对应的 SelectionKey 的集合,通过
* SelectionKey 可以找到对应的 Channel
*/
public abstract Set<SelectionKey> selectedKeys();
......
/**
* 返回所有 Channel 对应的 SelectionKey 的集合,通过 SelectionKey
* 可以找到对应的 Channel
*/
public abstract Set<SelectionKey> keys();
......
/**
* 监控所有注册的 Channel,当其中的 Channel 有 IO 操作可以进行时,
* 将这些 Channel 对应的 SelectionKey 找到。参数用于设置超时时间
*/
public abstract int select(long timeout) throws IOException;
/**
* 无超时时间的 select 过程,一直等待,直到发现有 Channel 可以进行
* IO 操作
*/
public abstract int select() throws IOException;
/**
* 立即返回的 select 过程
*/
public abstract int selectNow() throws IOException;
......
/**
* 唤醒 Selector,对无超时时间的 select 过程起作用,终止其等待
*/
public abstract Selector wakeup();
}
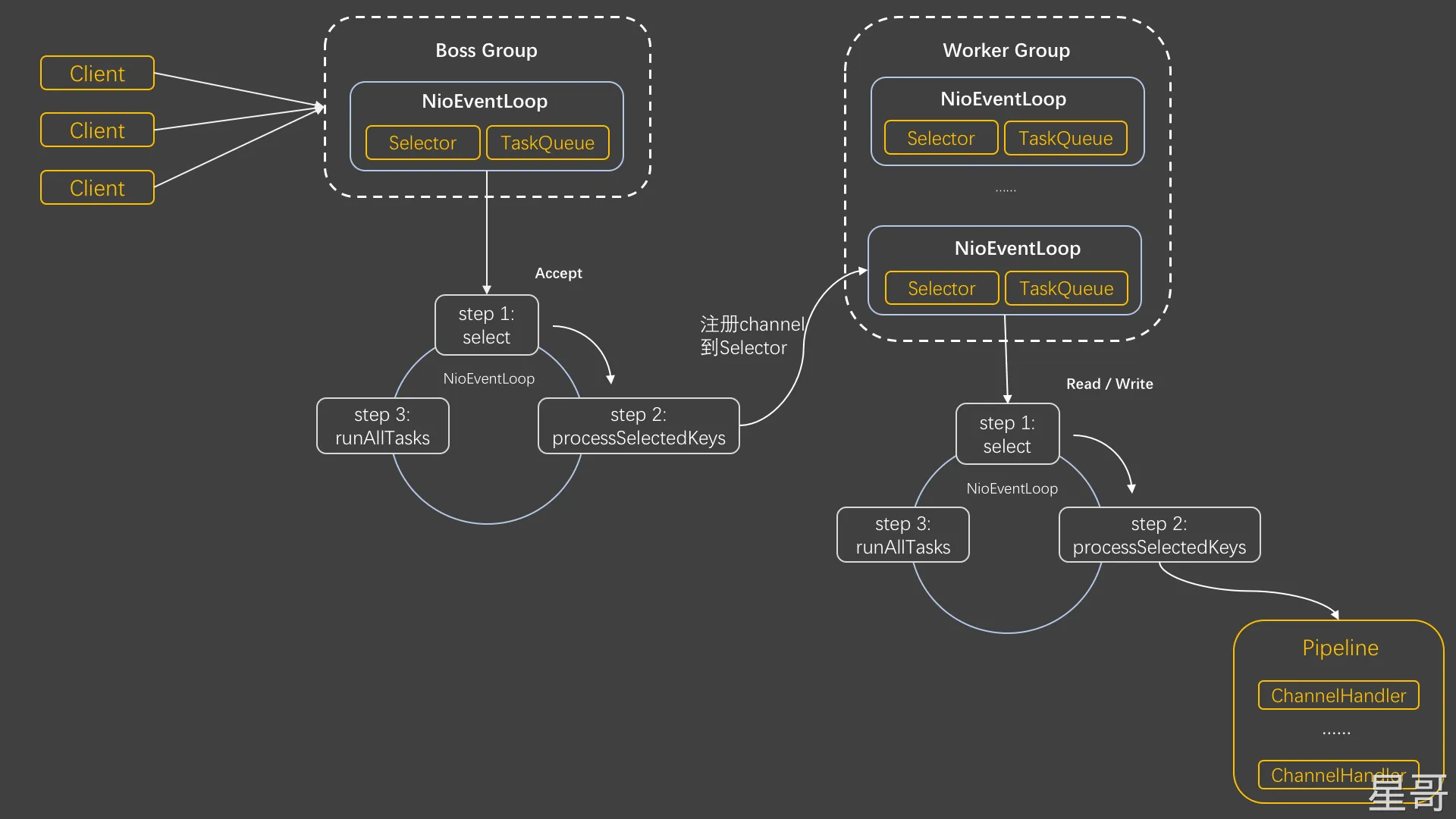
流程
ServerSocketChannel绑定端口- 设置
ServerSocketChannel为非阻塞 - 注册
ServerSocketChannel到selector,关注OP_ACCEPT事件 - 开启一直循环,调用
selector.select()或select(long timeout)阻塞住,等待客户端的调用 - 客户端调用后,执行
selector.selectedKeys()返回事件集合 - 遍历事件集合,判断其事件状态
- 如果是
OP_ACCEPT事件,则调用serverSocketChannel.accept()获得客户端的SocketChannel,将socketChanne也注册到selector,关注OP_READ事件 - 如果是
发生 OP_READ 事件,读客户端数据
netty重要的概念
总结
- 一个
EventLoopGroup当中会包含一个或多个EventLoop。 - 一个
EventLoop在它的整个生命周期当中都会与唯一一个Thread进行绑定。 - 所有由
EventLoop所处理的各种I/O事件都将在它所关联的那个Thread上进行处理。 - 一个
Channel在它的整个生命周期中只会注册在一个EventLoop上。也就是一个Channel中的多个ChannelHandle都是由一个线程处理的。 - 一个
EventLoop在运行过程当中,会被分配给一个或多个Channel。 - 由第4、5点可知,在
channelHandler中不要用耗时时间长的逻辑操作,否则整个ChannelPipeline的channelHandler都会受到影响。
记录
结构图
channel ChannelPipeline ChannelHandler ChannelHandlerContext 的关系
- 每个
channel里会创建一个ChannelPipeline(是一个双向链表) - 每创建一个
ChannelHandler都会有对应的一个ChannelHandlerContext(其实ChannelHandler是ChannelHandlerContext成员对象) - 将每个
ChannelHandler对应的ChannelHandlerContext都会添加到ChannelPipeline的链表中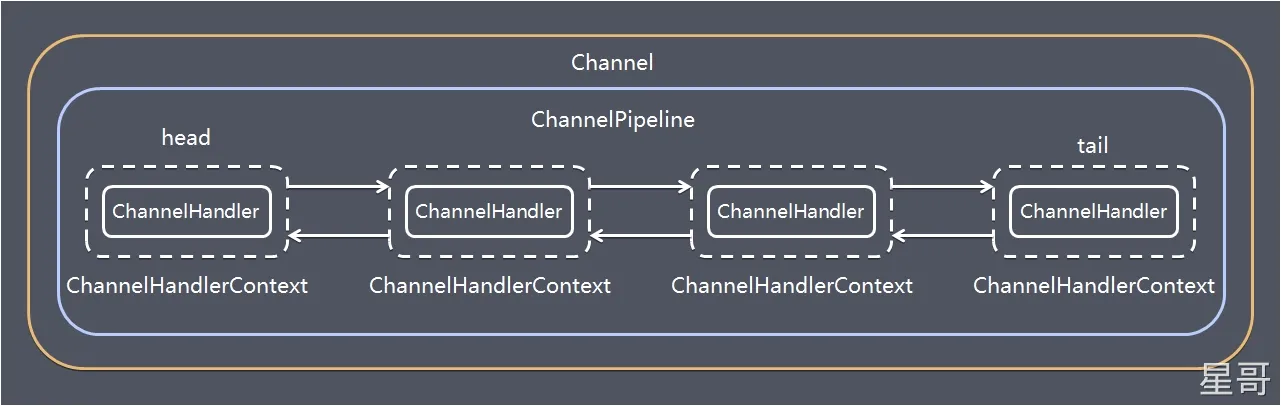
initChannel官方介绍
/**
* This method will be called once the {@link Channel} was registered. After the method returns this instance
* will be removed from the {@link ChannelPipeline} of the {@link Channel}.
*
* @param ch the {@link Channel} which was registered.
* @throws Exception is thrown if an error occurs. In that case it will be handled by
* {@link #exceptionCaught(ChannelHandlerContext, Throwable)} which will by default close
* the {@link Channel}.
*/
protected abstract void initChannel(C ch) throws Exception;
改进
channel,ChannelHandlerContext的attr设置属性所处于的作用域是不同的。
- 在netty4.1前
channel,ChannelHandlerContext的attr设置属性时,每个ChannelHandlerContext都有自己的map、channel也有自己的map,来存储设置的属性。这样做很浪费内存. - 在netty4.1后
channel,ChannelHandlerContext的attr设置属性时,每个ChannelHandlerContext都是设置到channel的map里,就变成了只有一个map,这样就可以节省了内存 - 网址 www.open-open.com/news/view/a94658
ChannelFuture官网介绍
* +---------------------------+
* | Completed successfully |
* +---------------------------+
* +----> isDone() = true |
* +--------------------------+ | | isSuccess() = true |
* | Uncompleted | | +===========================+
* +--------------------------+ | | Completed with failure |
* | isDone() = false | | +---------------------------+
* | isSuccess() = false |----+----> isDone() = true |
* | isCancelled() = false | | | cause() = non-null |
* | cause() = null | | +===========================+
* +--------------------------+ | | Completed by cancellation |
* | +---------------------------+
* +----> isDone() = true |
* | isCancelled() = true |
* +---------------------------+
public interface ChannelFuture extends Future<Void>
重要结论:
- 在Netty中,
Channel的实现一定是线程安全的;基于此,我们可以存储一个Channel的引用,并且在需要向远程端点发送数据时,通过这个引用来调用Channel相应的方法;即便当时有很多线程都在使用它也不会出现多线程问题;而且,消息一定会按照顺序发送出去。 - 我们在业务开发中,不要将长时间执行的耗时任务放入到
EventLoop的执行队列中,因为它将会一直阻塞该线程所对应的所有Channel上的其他执行任务,如果我们需要进行阻塞调用或是耗时的操作(实际开发中很常见),那么我们就需要使用一个专门的EventExecutor(业务线程池)。
通常会有两种实现方式:
- 在ChannelHandler的回调方法中,使用自己定义的业务线程池,这样就可以实现异步调用。
- 借助于Netty提供的向ChannelPipeline添加ChannelHandler时调用的addLast方法来传递EventExecutor。
说明:
- 默认情况下(调用
addLast(handler)),ChannelHandler中的回调方法都是由I/O线程所执行,如果调用了ChannelPipeline addLast(EventExecutorGroup group, ChannelHandler... handlers);方法,那么ChannelHandler中的回调方法就是由参数中的group线程组来执行的。 - JDK所提供的
Future只能通过手工方式检查执行结果,而这个操作是阻塞的;Netty则对ChannelFuture进行了增强,通过ChannelFutureListener以回调的方式来获取执行结果,去除了手工检查阻塞的操作;值得注意的是:ChannelFutureListener的operationComplete方法是由I/O线程执行的,因此要注意的是不要在这里执行耗时操作,否则需要通过另外的线程或线程池来执行。
SimpleChannelInboundHandler ChannelInboundHandlerAdapter的关系和区别
SimpleChannelInboundHandler:
只要实现channelRead0方法就可以,netty会帮助我们来释放消息资源
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
System.out.println(ctx.channel().remoteAddress() + ", " + msg);
//这种会从channel的最后一个ChannelHandlerContext开始,一个个的向前调用
ctx.channel().writeAndFlush("from server: " + UUID.randomUUID());
//这种会从当前ChannelHandlerContext的前一个ChannelHandlerContext开始,一个个的向前调用
ctx.writeAndFlush();
}
注意:
在Netty中有两种发送消息的方式,可以直接写到Channel中,也可以写到与ChannelHandler所关联的那个ChannelHandlerContext中。对于前一种方式来说,消息会从ChannelPipeline的末尾开始流动;对于后一种方式来说,消息将从ChannelPipeline中的下一个ChannelHandler开始流动。
结论:
- ChannelHandlerContext与ChannelHandler之间的关联绑定关系是永远都不回发生改变的,因为对其进行缓存是没有任何问题的。
- 对于与Channel的同名方法来说,ChannelHandlerContext的方法将会产生更短的事件流,所以我们应该在可能的情况下利用这个特征来提升应用性能。
IO的byteBuffer
使用NIO进行文件读取所涉及的步骤:
- 从FileInputStream对象获取到Channel对象
- 创建Buffer
- 将数据从Channel中读取到Buffer对象中
0 <= mark <= postion <= limit <= capacity
flip()方法
- 将limit值设为当多年前的position
- 将position设为0
clear()方法
- 将limit值设为capacity
- 将position值设为0
compact()方法
- 将所有未读的数据复制到buffer起始位置处
- 将position设为最后一个未读元素的后面
- 将limit设为capacity
- 现在buffer就准备好了,但是不会覆盖未读的数据
ByteBuf
*
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* | | (CONTENT) | |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
*
注意:通过索引来访问Byte时并不会改变真实的读索引与写索引;我们可以通过ByteBuf的ReaderIndex()与writerIndex()方法分别直接修改读索引与写索引。
Netty ByteBuf所提供的3中缓存区类型:
- heap ByteBuf
- direct ByteBuf
- composite ByteBuf
Heap ByteBuf(堆缓冲区)
这是最常用的类型,ByteBuf将数据存储到JVM的堆空间中,并且将实际的数据存放到byte array中来实现。
优点:由于数据是存储在JVM的堆中,因此可以快速的创建与快速的释放,并且它提供了直接访问内部字节数组的方法。缺点:每次读写数据时,都需要先将数据复制到直接缓冲区中再进行网络传输。
Direct ByteBuf(直接缓冲区)
在堆之外直接分配内存空间,直接缓冲区并不会占用堆的容量空间,因为它是由操作系统在本地内存进行的数据分配。
优点:在使用socket进行数据传递时,性能非常好,因为数据直接位于操作系统的本地内存中,所以不需要从JVM将数据复制到直接缓冲区中,性能很好。缺点:因为Direct Buffer是直接在操作系统内存中的,所以内存空间的分配与释放要比堆空间更加复杂,而且速度要慢一些。
Netty通过提供内存池来解决这个问题,直接缓冲区并不支持通过数组的方法访问数据。
重点:
对于后端的业务消息的编解码来说,推荐使用HeapByteBuf;对于I/O通信线程在读写缓冲区时,推荐使用DirectByteBuf。composite ByteBuf(复合缓冲区)
JDK的ByteBuffer与Netty的ByteBuf之间的差异对比:
- Netty的
ByteBuf采用了读写索引分离的策略(readerIndex与writerIndex),一个初始化(里面尚未有任何数据)的ByteBuf的readerIndex与writerIndex值都为0。 - 当读索引与写索引处于同一个位置时,如果我们继续读取,那么就会抛出
IndexOutOfBoundsException。 - 对于
ByteBuf的任何读写操作都会分别单独维护读索引与写索引。maxCapacity最大容量默认就是Integer.MAX_VALUE。
JDK的ByteBuffer的缺点:
final byte[] bb;这是JDK的ByteBuffer对象中用于存储数据的对象声明;可以看到,其字节数组是被声明为final的,也就是长度是固定不变的。一旦分配好后,就不能动态扩容与收缩;而且当待存储的数据字节很大时就很有可能出现IndexOutOfBoundsException,如果要预防这个异常,那就需要在存储之前完全确定好待存储字节大小。如果ByteBuffer的空间不足,我们只有一种解决方法:创建一个全新的ByteBuffer对象,然后再将之前的ByteBuffer中的数据复制过去,这一切操作都需要开发者自己来手动完成。ByteBuffer只使用一个position指针来标识位置信息,在进行读写切换时就需要调用flip方法或是rewind方法,使用起来很不方便。
Netty的ByteBuf的优点:
- 存储字节的数组是动态的,其最大值默认是
Integer.MAX_VALUE。这里的动态性是体现在write方法中的,write方法在执行时会判断ByteBuf容量,如果不足则会自动扩容。 ByteBuf的读写索引是完全分开的,使用起来就很方便。