全面剖析分库分表
背景
在如今人人都参与互联网的年代,对于数据的存储来说,所面临的挑战也是越来越大。尤其对传统的关系型数据库 比如Mysql、Oracle来说,当数据越来越多,所面临的存储容量和执行效率也越来越慢的问题也越来越需要考虑。即使加的索引非常的合理,但随着表的量级越来越大,索引的容量也越来越大,效率始终还是下降。
为了应对这种问题,如今主流的方案有分布式数据库和分库分表两种方案存在
分布式数据的优点是上手简单,和正常的数据库用法相同,无需考虑分库分表、分片键、分片算法的问题,但目前的分布式数据对服务器的性能要求比较高,对于预算紧张的公司来说,不太适合。另外目前来说 分布式数据库的稳定性还不是如传统的Mysql、Oracle。
另一种就是常说的分库分表,其实分库分表是由 分库 和 分表 这两个独立概念组成的,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做 分库分表。
介绍
通过一定的规则,如果按时间范围划分,根据hash取模、指定分片等算法,将数据量大的数据库拆分成多个单独数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
为什么分库
第一个就是连接数的问题,虽然现在服务连接数据库都使用了数据源这种池化的缓存方案,但每个数据库的连接数始终是有上限的,当并发量突增,很快就会将数据库的连接全部用掉,其他的请求就会失败
第二个就是容量的问题,每台机器给数据库分配的磁盘容量是有限的,随着数据量的增加,依旧存在容量会被占满的问题
为什么分表
对于表来说,最需要考虑的问题就是sql的执行效率,导致sql执行效率慢的原因有很多,没命中索引、like 扫全表、用了函数计算等等。这些在数据量不大的时候以及用上索引问题都不是很大,但一旦表中的数据量很大的话,假如是一亿数据量,就算用上索引效率也不是很高,原因是 InnoDB 存储引擎,聚簇索引结构的 B+树的层级变高,磁盘 IO 变多查询性能变慢
索引的计算
首先,InnoDB存 储引擎最小储存单元是页,一页大小是 16k,B+树的叶子节点存的是每行完整的数据,非叶子节点存的是键值和指针。
索引的查找过程:
- 利用二分查找法在非叶子节点中查找,最终落到叶子节点,也就是落到页中
- 进而去页中找到需要查找的数据
计算
-
假设表中每行的记录数据大小是
1k,则每个叶子节点能存储的记录数为;16K / 1K = 16 -
主键使用
bigint类型,长度为8字节,指针的大小在InnoDB中占用6字节,所以一共是 14字节。则每个非叶子节点的记录数为
我们假设这颗B+树的高度为3,那么这棵B+树的存放总记录数 = 根非叶子节点保存记录数 * 根节点下每个记录数的非叶子节点记录数 * 单个叶子节点记录行数
将数据代理计算:1170 * 1170 * 16 = 21902400 ,也就是说在表中每行记录大小为1k的情况下,高度为 3 的B+树所存储的记录大概为 2千万 左右。
所以分表要根据表的记录和每行记录的大小来解决是否分表。在Alibaba的开发规范手册中给出了建议
单表行数超 500 万行或者单表容量超过 2GB,推荐分库分表
垂直拆分
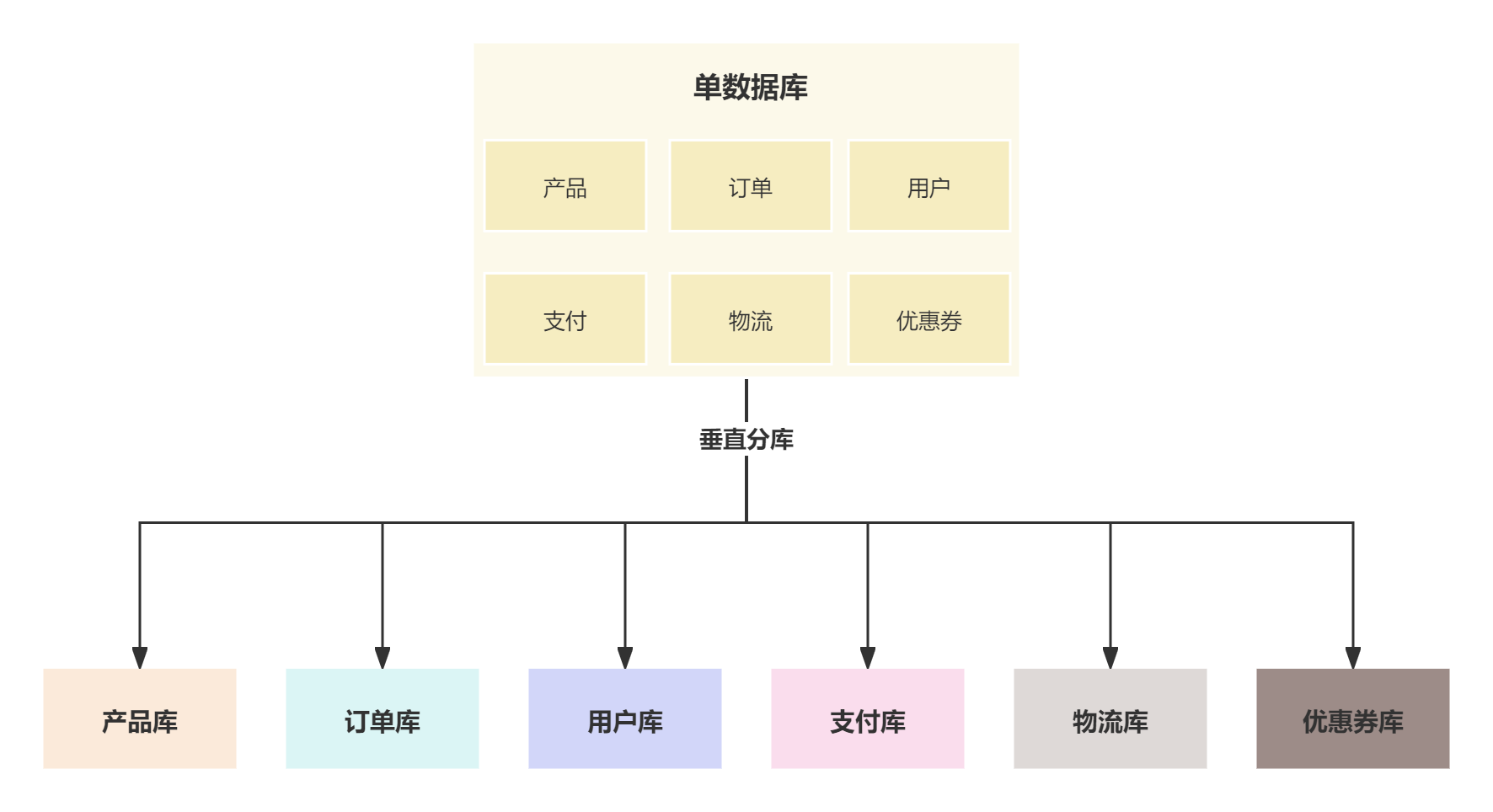
垂直分库
在开始规模比较小的单体项目来说,所有的业务都是放在同一个数据库中,比如产品、订单、用户、支付都是在同一个库中,但随着项目越来越庞大,数据量也越来越大,就需要按照不同的业务来拆分成多个库
垂直分表
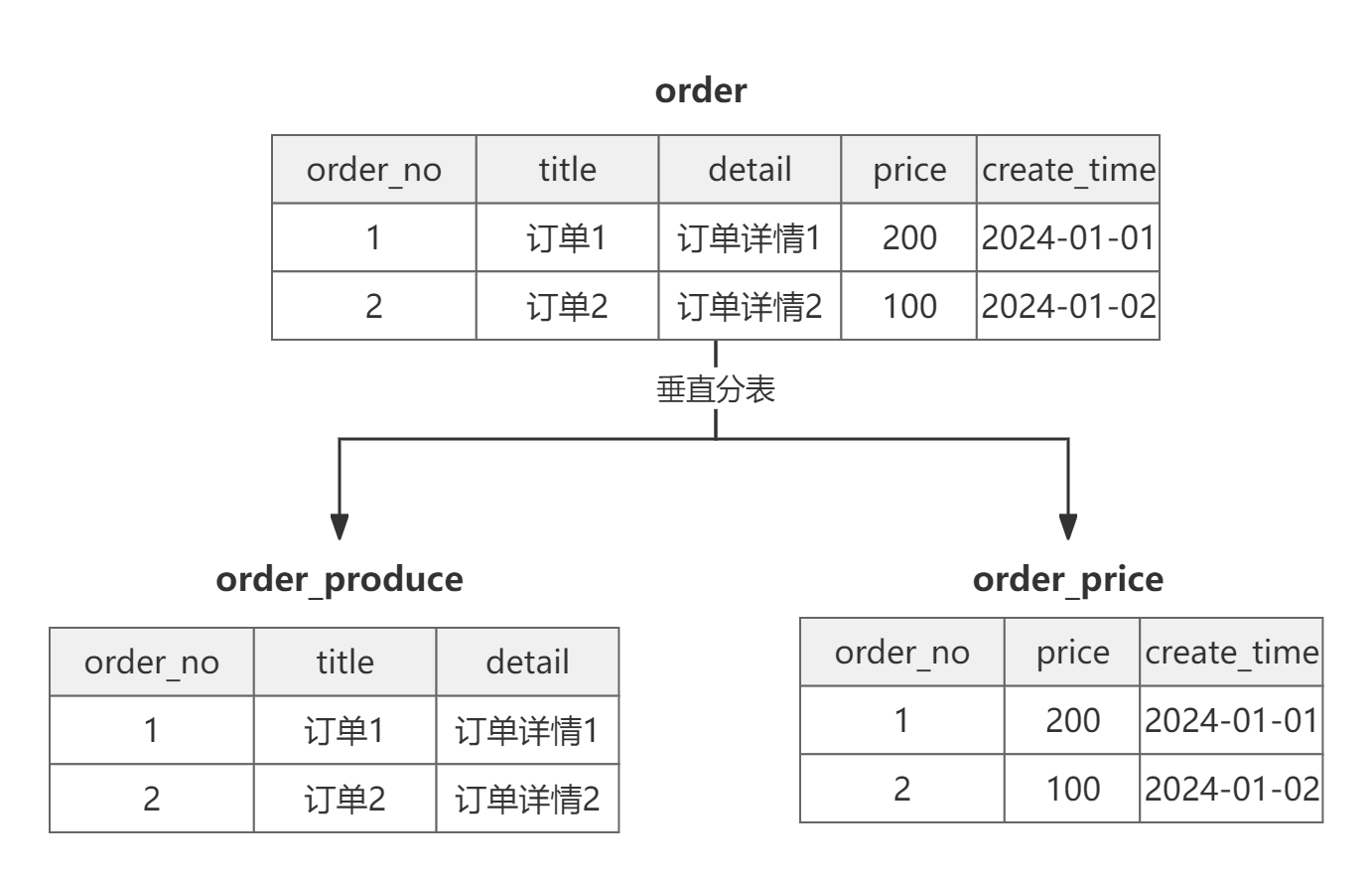
垂直分表适用于字段非常多的表,对于很多的查询来说,其实不需要一次将所有的字段全都查询出来,这样很浪费性能,影响效率,那么就将经常查询的字段单独拆分出一个表,将另外的字段单独拆分成另一个表,拆分后的表通过某个字段关联起来,这样既可以减少表的容量大小,又可以提升查询效率
水平拆分
垂直拆分其实还是根据业务进行模块话拆分的,当单表的容量越来越大的时候,还是不能解决单表的读写、存储的性能瓶颈,这是就需要水平拆分了
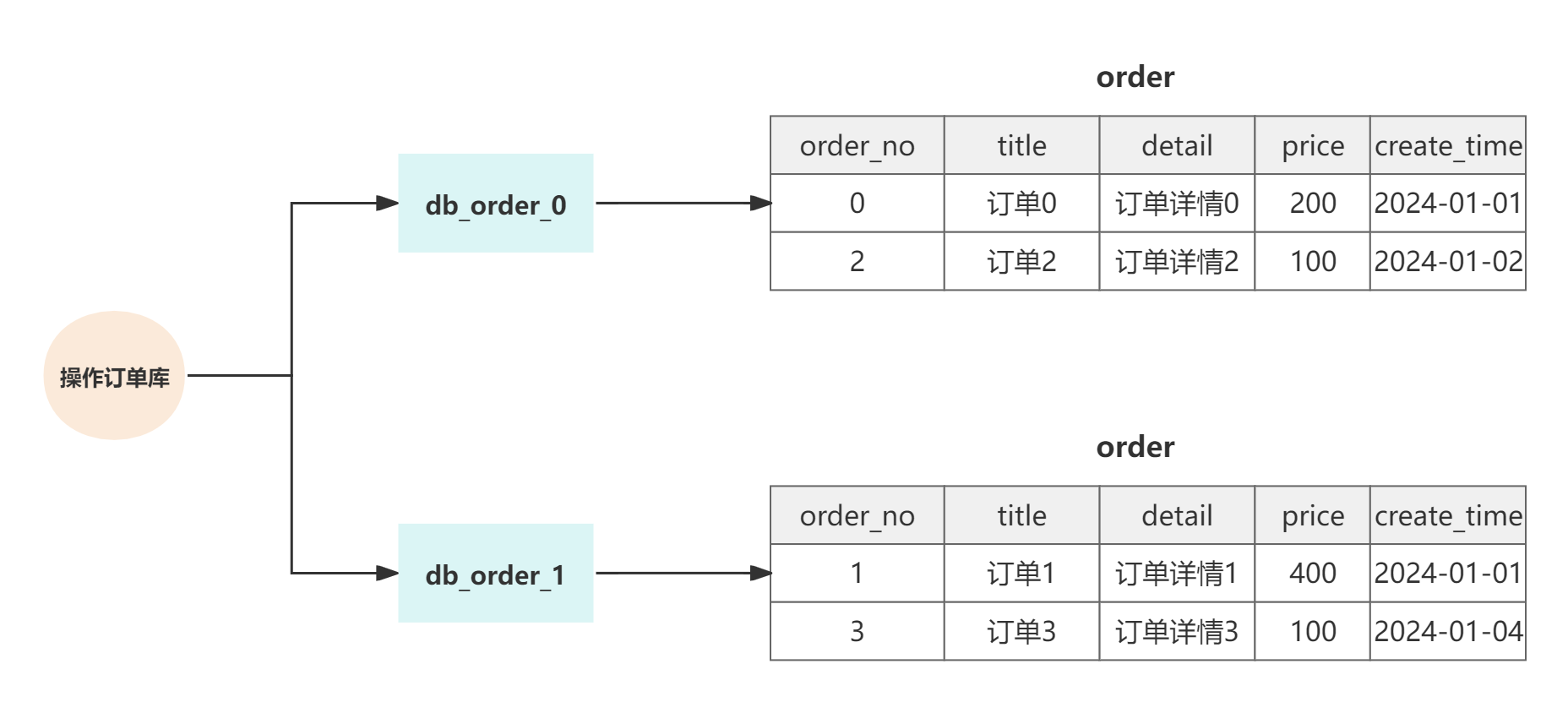
水平分库
水平分库是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,每个数据库的库和表结构都是相同的,只有表中的数据不同。可以实现水平扩展,有效缓解单裤的性能瓶颈
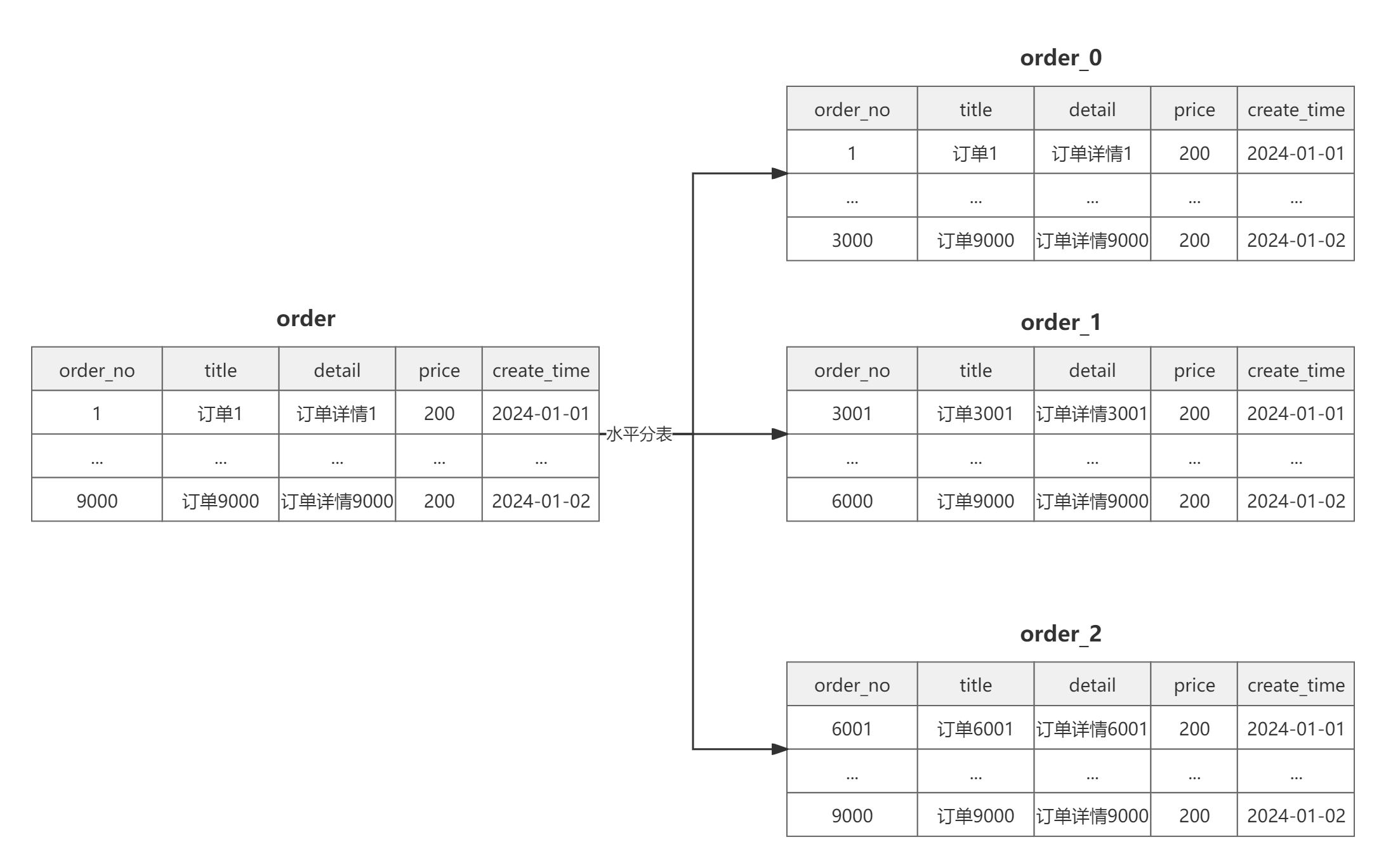
水平分表
水平分表是在同一个数据库内,对大表进行水平拆分,分割成多个表结构相同的表
支持的中间件
目前对分库分表支持的中间件比较多,但在社区热度和发展规模以及使用的程序来看,能用的差不多有 ShardingSphere 和 Mycat
如果在这两者中进行选型的话,无论在使用和完善以及热度上, ShardingSphere 可以说是降维打击 Mycat 了,在大麦网项目中,也会选择 ShardingSphere 作为分库分表的支持
下面两者的地址,有兴趣的小伙伴可以去研究
ShardingSphere
由于选择了 ShardingSphere ,所以对重要的特征进行介绍,如果想了解详情,可去官网查看
ShardingSphere-JDBC
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务
ShardingSphere-Proxy
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持
可以理解成 ShardingSphere-Proxy 伪装成了 Mysql,我们直接操作这个伪装的 Mysql 即可,但性能上肯定还是不如直接使用 ShardingSphere-JDBC 进行分库分表
概念
对于 ShardingSphere 的使用,需要先去理解一些概念,比如 表、 逻辑表、 真实表、 绑定表、 广播表、 单表等,以及 什么是 分片键 、分片算法,具体详情可跳转到官网介绍
分片算法
ShardingSphere 对于分片算法有非常灵活的配置,对于常见的分片算法,如 MOD(取模)、HASH_MOD(哈希取模)、BOUNDARY_RANGE(分片边界的范围)都有默认的支持,并且也可以自定义实现分片算法,包括单分片键、复合分片键
细节问题
分片键的选择
如何选择分片键在分库分表中非常的重要,可以说直接影响了整个分库分表的性能,如果分片键选择不当,很可能会导致 全路由 查询,也就是将分库分表的中所有的库以及所有的表都要路由一遍,这样效率是非常低下的,所以一定要慎重考虑分片键。从以下方面来考虑
-
业务相关性:分片键应该与业务密切相关,能够反映出数据访问的模式。通常,选择那些经常作为查询条件的字段作为分片键,可以减少跨分片的查询,提高查询效率。
-
均匀分布数据:理想的分片键能够确保数据在各个分片间均匀分布,避免某些分片数据量过大而成为瓶颈。均匀的数据分布有助于负载均衡,提升整体性能。
-
写入性能:在考虑分片键时,应考虑到写入操作的性能。一个好的分片键可以减少写入时的热点问题,避免某个分片因为频繁的写入操作而过载。
-
避免频繁修改:分片键一旦选择并开始使用后,修改起来将非常困难且成本很高。因此,应选择那些不会或很少需要修改的字段作为分片键。
-
考虑未来的扩展性:在选择分片键时,还需要考虑到数据量增长和系统扩展的需要。分片键的选择应该能够适应数据量的增加,允许在不影响现有系统的前提下添加更多的分片。
-
避免业务操作跨分片:如果业务操作需要跨多个分片进行,可能会严重影响性能。因此,应尽可能选择可以将相关数据局部化的分片键,减少跨分片操作的需求。
-
安全和隐私考虑:在某些情况下,分片键的选择还需要考虑数据的安全和隐私要求。例如,使用敏感信息(如用户ID)作为分片键时,需要确保分片策略遵守相关的数据保护法规。
历史数据的迁移
分库分表的方案确实使用后,有个一定要考虑的问题,就是如何平滑的迁移历史数据,增量数据和全量数据迁移
查询
一般用表中的id是分片键的最佳选择,但存在一个问题,比如搜索条件的分页查询,比如说查询职员列表,可根据 职员类型、所在部门、入职时间 这些条件查询列表,这些条件没有 职员id 的分片键,就会造成全路由的问题,那么要去怎么解决呢?
以上问题在大麦网中已经得到了解决,小伙伴可跳转到项目中的介绍章节来进行学习