大麦AI项目技术架构
架构设计
项目在使用 AI 模型时,有多个模块功能,包括 Springboot 和 SpringAI 的结合、RAG深度使用和如何自定义、 向量数据库的解释、SpringAI 操作向量数据库、MCP 和 Function Calling 操作数据、AI的拦截器 Advisor 的高阶用法 等等... ...
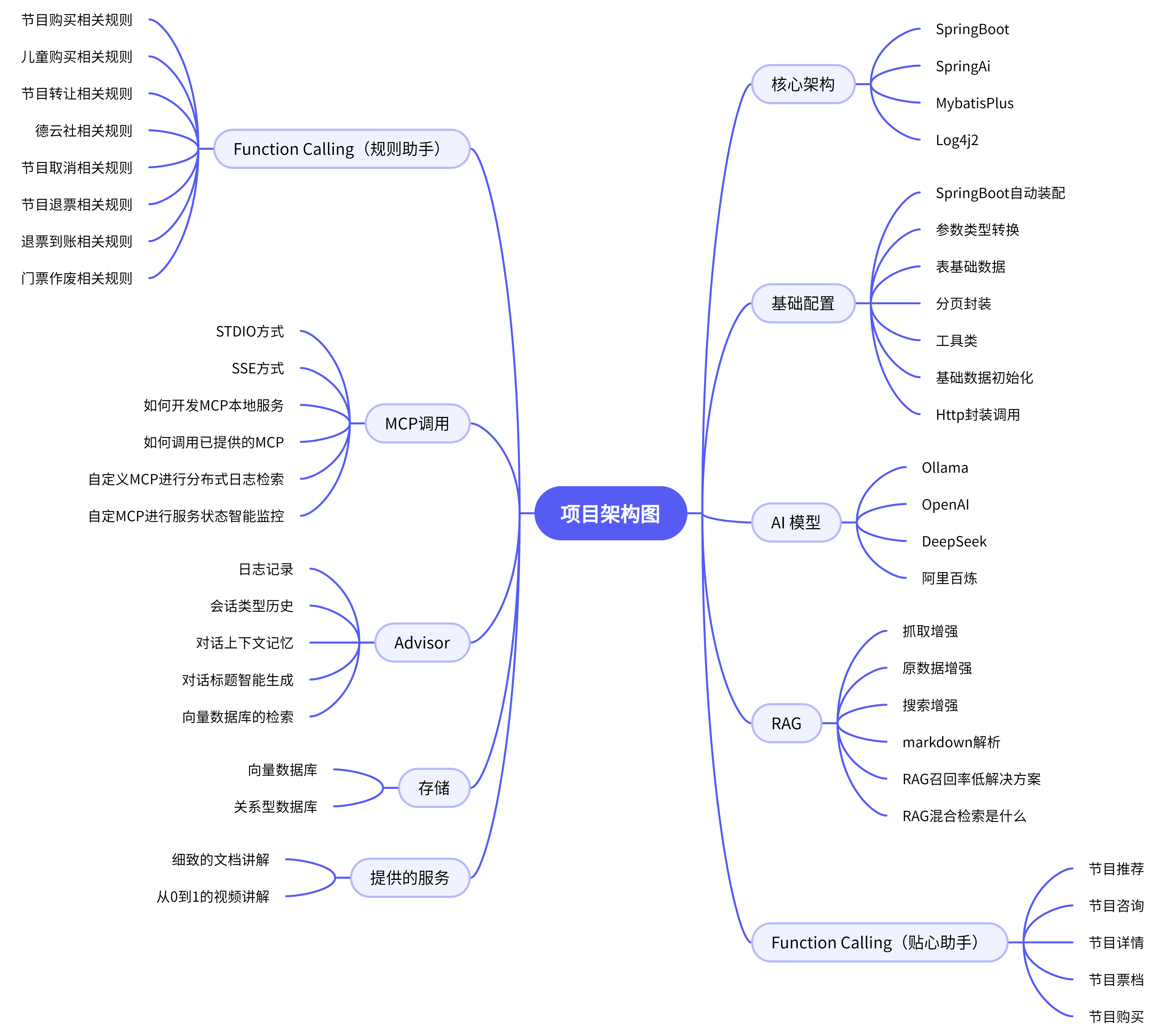
业务结构
通过此业务结构图进一步详细的介绍项目中的功能,包括:核心架构、AI模型、Advisor、RAG、基础配置、贴心助手、规则助手、调用方式、存储方式等各个方面,能够对大麦AI项目的整体架构和设计有一个清晰的认知
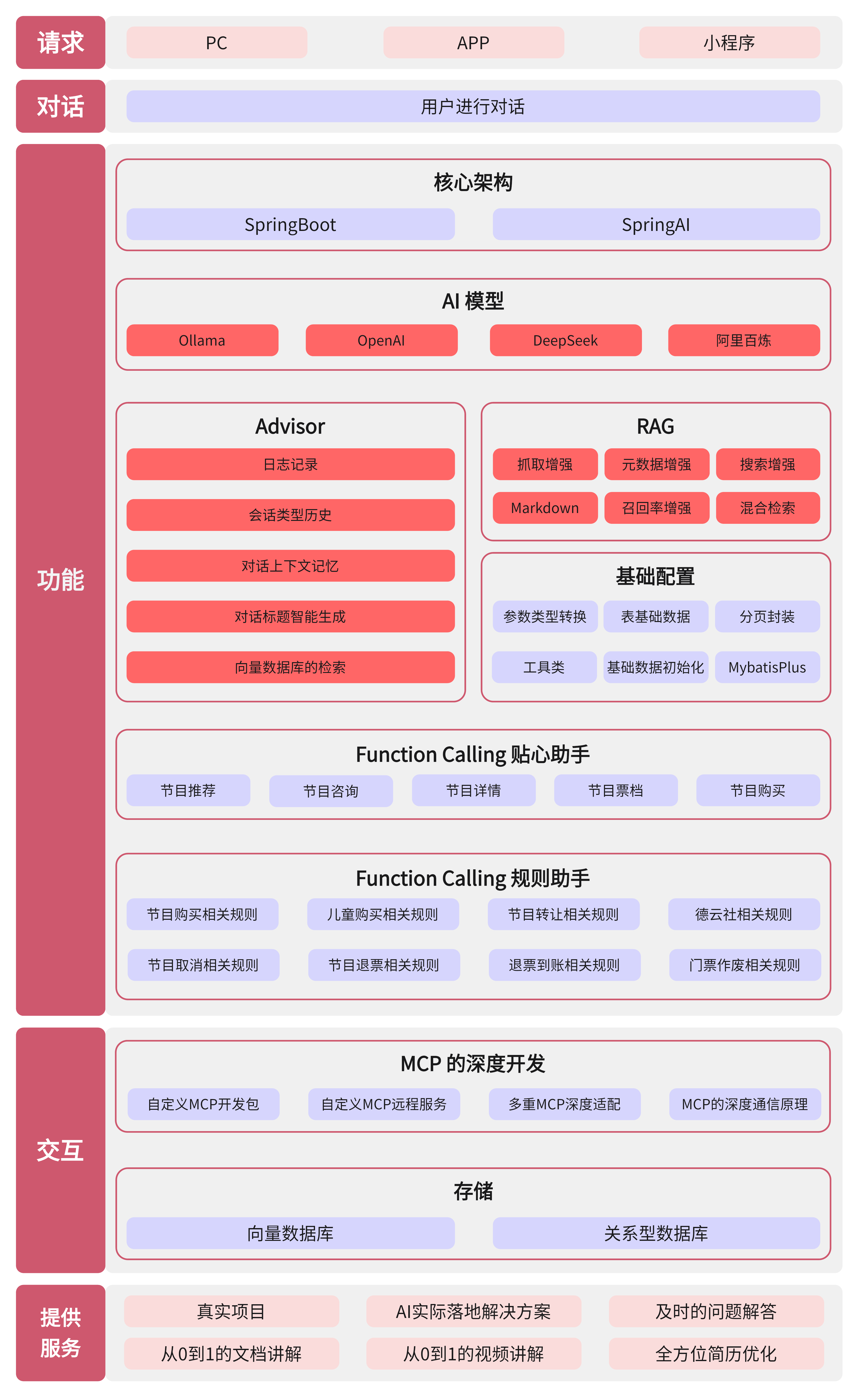
项目的技术架构
整体设计
项目分成三层:
前端用的Vue 3,做了一个聊天界面。用户在这里跟AI对话,支持多轮聊天、历史记录管理、流式输出这些功能。
后端用的Spring Boot + Spring AI框架。Spring AI是Spring官方的AI框架,用起来很顺手。我们对接了DeepSeek和通义千问两个大模型,DeepSeek做主力推理,通义千问做向量化。
MCP服务是独立部署的工具服务。日志查询是一个MCP服务,监控指标是另一个MCP服务。这样设计的好处是解耦,工具服务可以独立扩展,也方便后面加新的工具。
核心能力
Function Call 是关键技术之一。我们给大模型定义了一系列工具函数,比如查询节目、查询票档、创建订单。大模型会根据用户的意图,自动选择合适的工具来执行。用户说"帮我查一下周杰伦的演唱会",大模型就会调用查询节目的函数,拿到结果后再组织语言回复用户。
RAG(检索增强生成) 用在规则助手里。我们把订票规则、退票政策这些文档做了向量化,存到向量数据库里。用户提问的时候,先从知识库里检索相关内容,再把检索到的内容和问题一起发给大模型,让大模型基于这些真实的信息来回答。这样就不会出现大模型"胡说八道"的情况了。
SSE流式输出 解决了用户等待的问题。大模型生成回复需要时间,如果等它全部生成完再返回,用户要干等好几秒。用SSE的话,大模型生成一个字就推送一个字,用户能看到文字一个个蹦出来,体验好多了。
多轮对话记忆 让AI能记住上下文。用户问"有没有便宜点的票",AI得知道用户之前问的是哪个节目。我们用MessageWindowChatMemory来管理对话历史,保留最近20轮对话,太老的就总结一下存起来,避免上下文太长导致token超限。
三个助手的详细介绍
麦小蜜 - 购票助手
麦小蜜是面向普通用户的购票助手。它的核心职责是帮用户完成购票全流程。
节目推荐:用户说想看演唱会,麦小蜜会先问清楚想在哪个城市看、想看什么类型的,然后从数据库里查出符合条件的节目推荐给用户。
节目咨询:用户想了解某个节目的详情,比如演出时间、地点、阵容,麦小蜜会调用节目详情接口,把信息整理好告诉用户。
票档查询:用户想知道有什么价位的票、还剩多少张,麦小蜜会查询票档信息。不过我们有个规则,不能直接告诉用户具体剩多少张,只告诉用户还有票或者已售罄。
下单购买:用户决定要买了,麦小蜜会引导用户提供手机号、购票人证件号、选哪个票档、买几张。收集完信息后,调用订单服务创建订单,告诉用户订单号,引导用户去支付。
麦小蜜的prompt写得很细,把各种场景的处理流程都规定好了,还加了安全防护,防止用户通过prompt注入来绕过规则。
麦小维 - 运维分析助手
麦小维是给运维同学用的分析助手。它主要干这几件事:
日志查询:运维同学可以直接问"帮我查一下order-service最近的错误日志",麦小维会调用日志查询MCP工具,从ES里查出日志返回给用户。支持按关键词搜索、按服务名筛选、按日志级别过滤。
链路追踪:给一个traceId,麦小维能帮你查出这个请求经过了哪些服务,每个服务打了什么日志,哪个环节出了问题。这个功能排查分布式系统的问题特别好用。
监控指标:麦小维能查询JVM内存、CPU使用率、线程数、GC情况这些指标。它会调用Prometheus的API,拿到数据后分析一下,告诉你是不是有异常。
问题分析:这是比较智能的功能。你告诉麦小维"order-service响应很慢",它会先查错误日志,再查监控指标,综合分析后给出可能的原因和解决建议。
麦小维的能力主要靠MCP工具来实现。我们开发了两个MCP服务:damai-mcp-log-service负责日志查询,damai-mcp-metrics-service负责监控指标查询。
规则助手 - 知识库问答
规则助手用来回答那些"政策性"的问题,比如:
- 演唱会能不能退票?
- 退票扣多少手续费?
- 一个账号能买几张票?
这类问题的答案都在我们的规则文档里,不需要实时查数据库。所以我们用了RAG的方案:
- 把规则文档(Markdown格式)切分成小块
- 用text-embedding-v3模型把文档块转成向量
- 存到向量数据库里
用户提问的时候:
- 把问题也转成向量
- 在向量数据库里找最相似的几块文档
- 把问题和检索到的文档一起发给大模型
- 大模型基于文档内容生成回答
这样做的好处是,大模型不会瞎编。它只会基于我们提供的文档来回答,答案都是有据可查的。
怎么介绍这个项目
面试的时候介绍项目,建议按这个思路来:
先讲背景和痛点
"这个项目是给大麦购票系统做的AI助手。为什么要做呢?主要是解决两个问题:一是用户咨询量大,很多问题都是重复的,客服忙不过来;二是运维排查故障效率低,要在好几个系统之间来回切换。"
再讲解决方案
"我们做了三个AI助手。一个是购票助手麦小蜜,帮用户查节目、买票;一个是运维助手麦小维,帮运维查日志、看监控、分析问题;还有一个规则助手,用RAG技术回答订票规则、退票政策这类问题。"
然后讲技术实现
"技术栈是Spring Boot + Spring AI + Vue。核心技术用了Function Call让大模型能调用工具,用RAG做知识库问答,用SSE做流式输出,用MCP协议封装工具服务。大模型用的DeepSeek和通义千问。"
最后讲效果
"上线之后效果还不错。购票助手能处理大部分的常见咨询,减轻了客服的压力。运维助手把故障排查从原来的十几分钟缩短到一两分钟,效率提升很明显。"
面试官如果感兴趣,会追问具体的技术细节。这时候就可以展开讲RAG的实现、Function Call的原理、MCP的设计这些。