向量数据库的具体应用
向量数据库(Vector Database)
向量数据库是一种专门用于存储和检索向量的数据库。它索引、存储带有向量表示(嵌入向量)的数据对象(如文本段、文档片段、图像等),并提供高效的相似度搜索。查询时,系统将用户输入转为向量,与数据库中所有向量进行比对,快速返回那些在语义上最相似的条目(向量距离最近者)。可以把向量数据库想象成一个按内容相似性排序的图书馆索引:当你有查询时,就像给馆员一个关键词(向量),图书馆(向量数据库)会在语义上最相关的书籍(数据项)中帮你找答案。
主流向量数据库对比
目前常用的向量数据库及其特点包括:
- FAISS:Meta(Facebook)开源的向量检索库。它专注于近似最近邻搜索,支持多种索引算法,非常适合对性能要求极高的场景(如需要在数千万甚至上亿条向量中快速检索),并且支持 GPU 加速。但作为库使用,需要自行管理资源和部署。
- Pinecone:商业化的全托管向量数据库。它提供高可靠性、弹性伸缩的向量搜索服务,用户无需部署和维护基础设施。Pinecone 支持混合搜索(向量+关键词)、实时数据写入和大型向量集查询,适合企业级应用,但使用成本相对较高。
- Weaviate:开源的向量数据库。它除了向量搜索外,还支持基于 GraphQL 的灵活查询和知识图谱关系,可处理多模态数据。Weaviate 易于扩展,提供丰富的内置模块(如 OpenAI 嵌入模块等),适用于需要结构化语义关联的场景。
- 其他:例如 Milvus(开源,擅长大规模向量集;GPU 优化)、ChromaDB(轻量级,易于本地开发)、Qdrant(Rust 实现,强大的元数据过滤)等也很流行。总体而言,选型时可根据场景需求——规模、检索性能、部署复杂度和成本等因素进行权衡。例如,研究原型或小规模项目可选择 Chroma、FAISS 等开源方案;而对 SLA 要求高、数据量大的企业应用往往会采用 Pinecone、Weaviate 等托管/成熟解决方案。
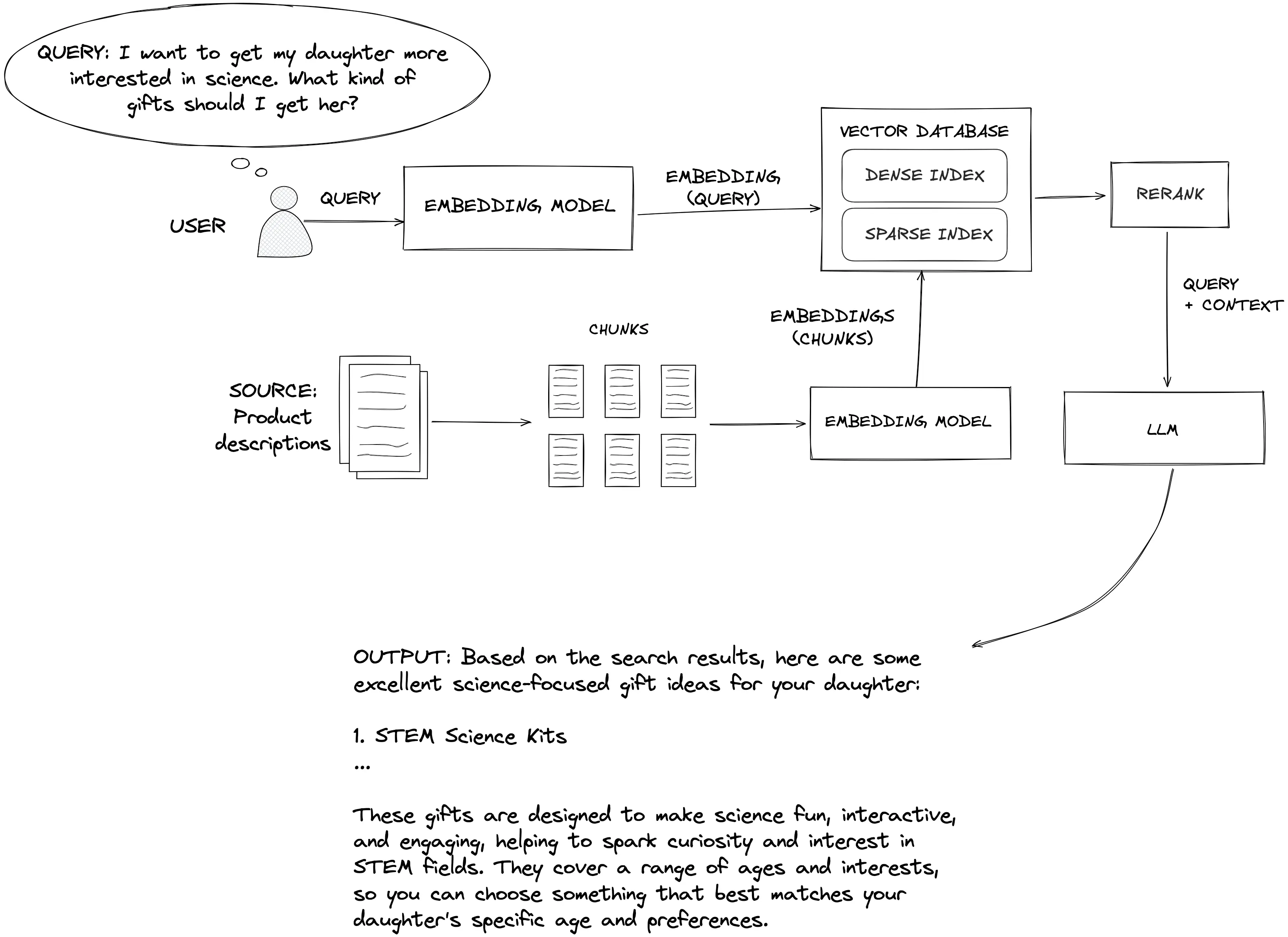
RAG 工作流程示意图
系统首先将原始文档或数据拆分并嵌入向量数据库,然后接收用户查询,将其转换为向量并检索相关文档片段,最后将检索到的信息与原始问题一同输入 LLM,生成最终回答。通过这种方式,生成模型不仅依赖自身“记忆”,还能实时参考外部知识,从而获得更准确、更可信的答案。
付费内容提示
该文档的全部内容仅对「JavaUp项目实战&技术讲解」知识星球用户开放
加入星球后,你可以获得:
- 超级八股文:100万+字的全栈技术知识库,涵盖技术核心、数据库、中间件、分布式等深度剖析的讲解
- 讲解文档:超级AI智能体、黑马点评Plus、大麦、大麦pro、大麦AI、流量切换、数据中台的从0到1的详细文档
- 讲解视频:超级AI智能体、黑马点评Plus、大麦、大麦pro、大麦AI、流量切换、数据中台的核心业务详细讲解
- 1 对 1 解答:可以对我进行1对1的问题提问,而不仅仅只限于项目
- 针对性服务:有没理解的地方,文档或者视频还没有讲到可以提出,本人会补充
- 面试与简历指导:提供面试回答技巧,项目怎样写才能在简历中具有独特的亮点
- 中间件环境:对于项目中需要使用的中间件,可直接替换成我提供的云环境
- 面试后复盘:小伙伴去面试后,如果哪里被面试官问住了,可以再找我解答
- 远程的解决:如果在启动项目遇到问题,本人可以帮你远程解决
进入星球后,即可享受上述所有服务,保证不会再有其他隐藏费用。
