Embedding向量化原理与模型选型
假设你是个媒人,手里有1000个单身男女的资料,要给他们配对。
每个人的资料是一段文字描述:
小王:28岁程序员,喜欢打游戏看动漫,宅男一枚,偶尔爬山
小李:26岁设计师,热爱旅行摄影,周末喜欢逛展览
小张:27岁产品经理,喜欢打篮球健身,性格外向
现在有个新人小美:"25岁,喜欢户外运动和摄影,希望找一个有共同爱好的人"
你怎么快速找出最适合小美的人选?
方法一:关键词匹配
搜索"户外运动"和"摄影",找到包含这些词的人。
问题是:小王的资料里写的是"爬山",不是"户外运动";小李的资料里写的是"旅行摄影",不是单独的"摄影"。关键词匹配可能漏掉他们。
方法二:理解语义
"爬山"和"户外运动"意思相近,"旅行摄影"也包含"摄影"的意思。如果能理解这层语义关系,就能找到真正匹配的人。
这就是Embedding要解决的问题——让机器理解文字的"意思",而不只是匹配字面。
Embedding(向量化)是将文字转换为高维数值向量的过程。其核心价值在于:语义相近的文字,在向量空间中的距离也近。这使得机器能够通过数学运算来理解和比较文字的"意思",而不仅仅是匹配字面字符。
什么是向量
在讲Embedding之前,先回顾一下高数里学过的向量。
向量就是一串数字
向量可以理解为一个带方向的箭头,用一组数字来表示:
- 一维向量:
[3],数轴上的一个点 - 二维向量:
[3, 4],平面上的一个点 - 三维向量:
[3, 4, 5],空间中的一个点
三维以上就不好画图了,但数学上没问题——可以是384维、768维、1536维,这些就叫高维向量。
向量能表示什么
在RAG场景里,向量用来表示文字的语义特征。
每个维度代表一个"语义方向",比如(这是打比方,实际不是这么简单):
- 第1维:是否涉及"人物"
- 第2维:是否涉及"动作"
- 第3维:是否涉及"时间"
- 第4维:是否涉及"技术"
- ...
一段文字被转成向量后,每个维度上的数值就表示这段文字在这个"语义方向"上的权重。
向量之间的距离
这是关键点——语义相近的文字,向量在空间中的距离也近。
"打印机怎么用" → [0.23, -0.45, 0.67, ...]
"产品使用方法" → [0.25, -0.42, 0.65, ...] ← 很接近
"今天天气不错" → [-0.89, 0.12, 0.03, ...] ← 差很远
这就是为什么向量检索能做语义匹配——不是比字面,是比"意思"。
向量空间的可视化
在这种表示下,语义相近的内容会在向量空间中聚集(距离更近)。例如,"猫""狗"等词的向量在空间中会聚在一起,因为它们都是"动物"相关词;而与车辆相关的词则聚成另一簇。
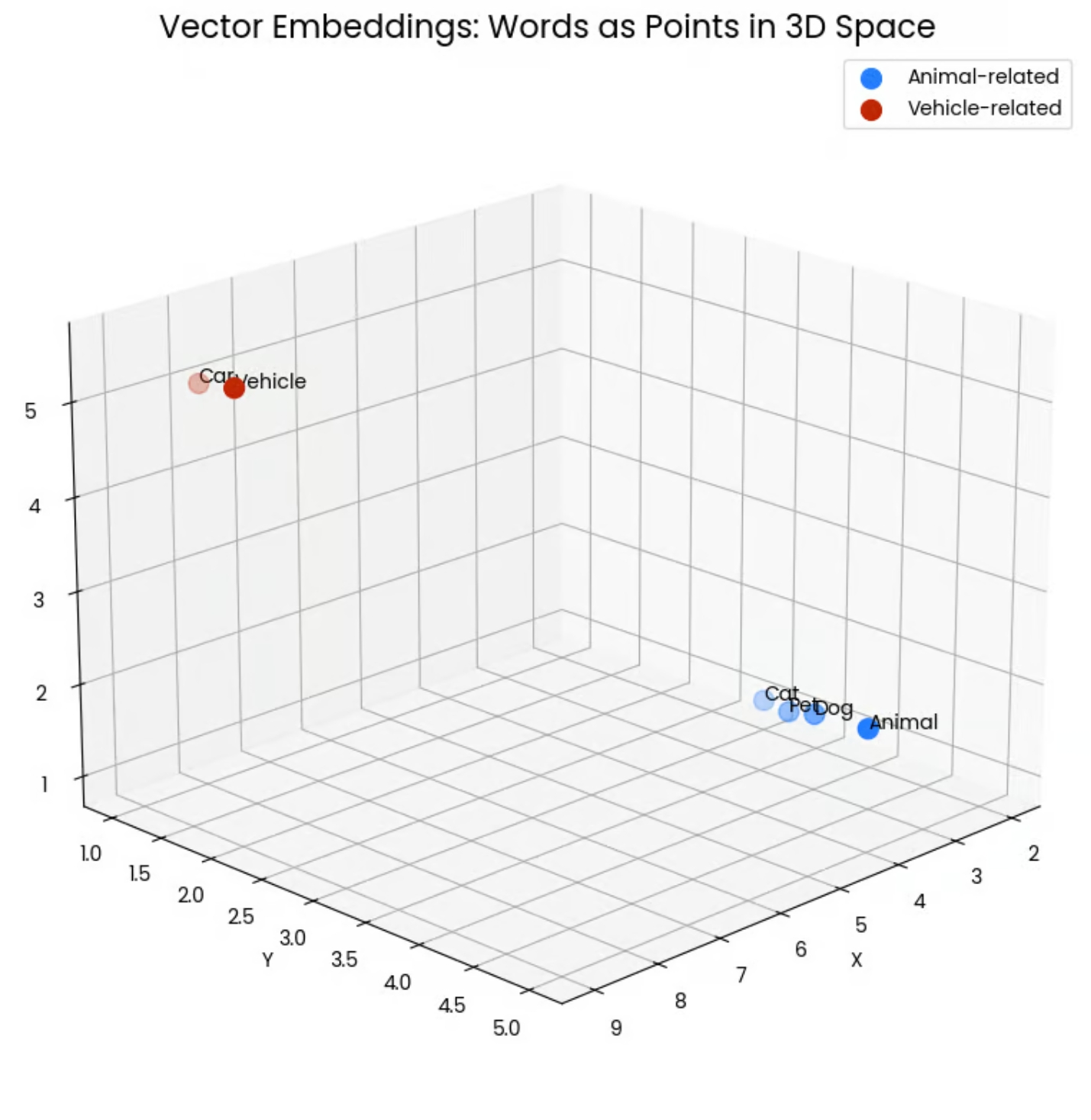
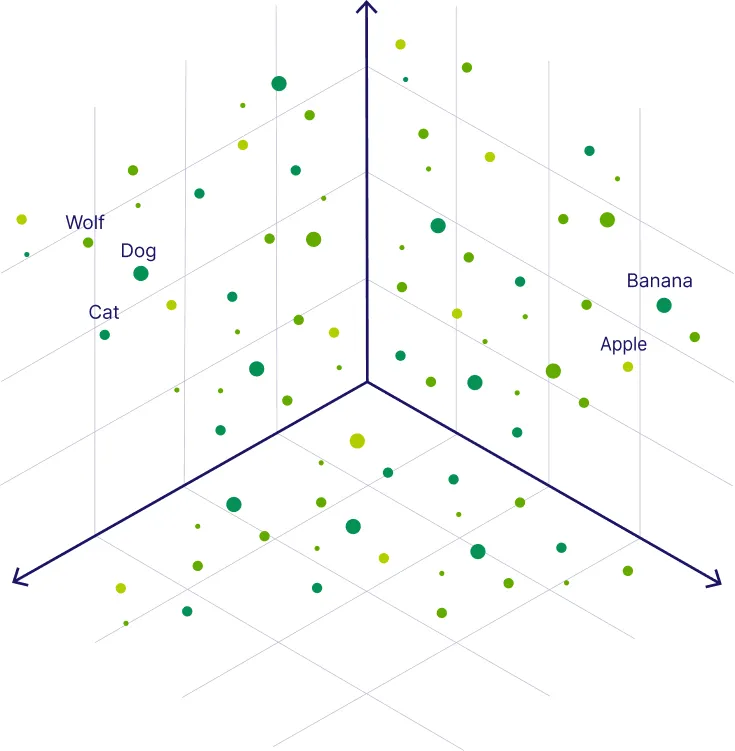
下图展示了更多词汇在向量空间中的分布,可以看到同类概念自然聚集:
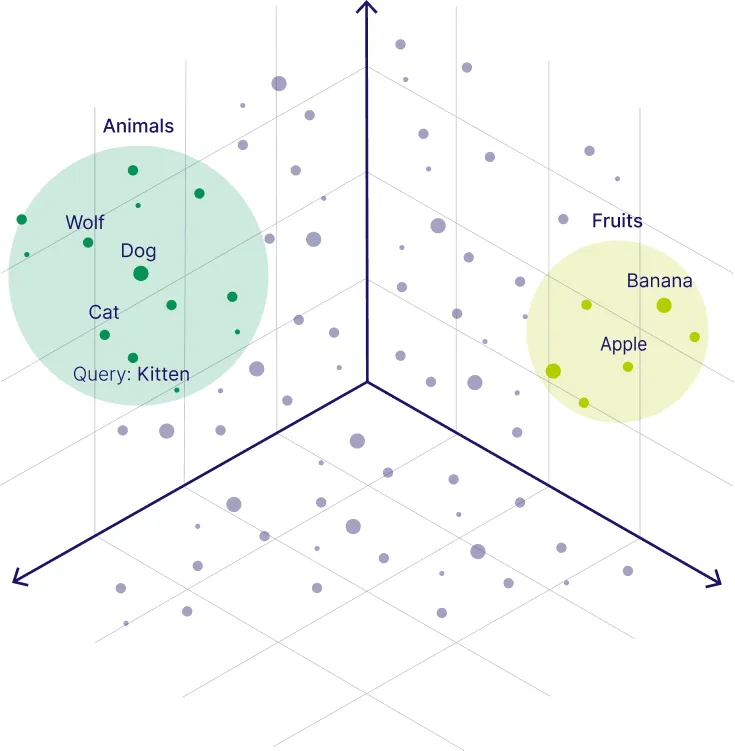
通过向量表示,模型可以量化语义相似度——两个内容的向量越接近,它们的含义就越相近。下图展示了"Animals"(动物类:Wolf、Dog、Cat)和"Fruits"(水果类:Banana、Apple)两个语义簇,当查询"Kitten"时,它会自动落在动物类聚簇附近:
付费内容提示
该文档的全部内容仅对「JavaUp项目实战&技术讲解」知识星球用户开放
加入星球后,你可以获得:
- 超级八股文:100万+字的全栈技术知识库,涵盖技术核心、数据库、中间件、分布式等深度剖析的讲解
- 讲解文档:超级AI智能体、黑马点评Plus、大麦、大麦pro、大麦AI、流量切换、数据中台的从0到1的详细文档
- 讲解视频:超级AI智能体、黑马点评Plus、大麦、大麦pro、大麦AI、流量切换、数据中台的核心业务详细讲解
- 1 对 1 解答:可以对我进行1对1的问题提问,而不仅仅只限于项目
- 针对性服务:有没理解的地方,文档或者视频还没有讲到可以提出,本人会补充
- 面试与简历指导:提供面试回答技巧,项目怎样写才能在简历中具有独特的亮点
- 中间件环境:对于项目中需要使用的中间件,可直接替换成我提供的云环境
- 面试后复盘:小伙伴去面试后,如果哪里被面试官问住了,可以再找我解答
- 远程的解决:如果在启动项目遇到问题,本人可以帮你远程解决
