图数据库与知识路由
前面几篇文档讲了检索链路、前置编排、双通道检索这些核心能力。但有一个问题一直没展开说:用户提了一个问题,系统怎么知道应该去哪份文档里找答案?
如果知识库里只有两三份文档,这不是问题。但当文档数量上了几十份甚至上百份,每次都全库检索,不仅慢,而且噪声会很大——用户问的是"年假怎么申请",结果从产品手册里也检索出了包含"申请"这个词的段落,这就是典型的 跨域干扰。
超级 AI 智能体项目用了两个手段来解决这个问题:
- Neo4j 图数据库:把每份文档的内部结构(章节、段落、条目)建成一张图,让系统能沿着文档结构精准导航,而不是只靠向量匹配碰运气
- 知识路由三级漏斗:在进入检索链路之前,先通过 Scope → Topic → Document 三级排序,自动锁定最相关的文档
另外还有一个很巧妙的设计:影子路由,用来持续观测路由质量,后面会详细讲。
如果把文档入库、图谱建模、知识路由、混合检索、证据生成和影子路由放到一条线上看,会更容易理解这部分为什么叫“知识闭环”:
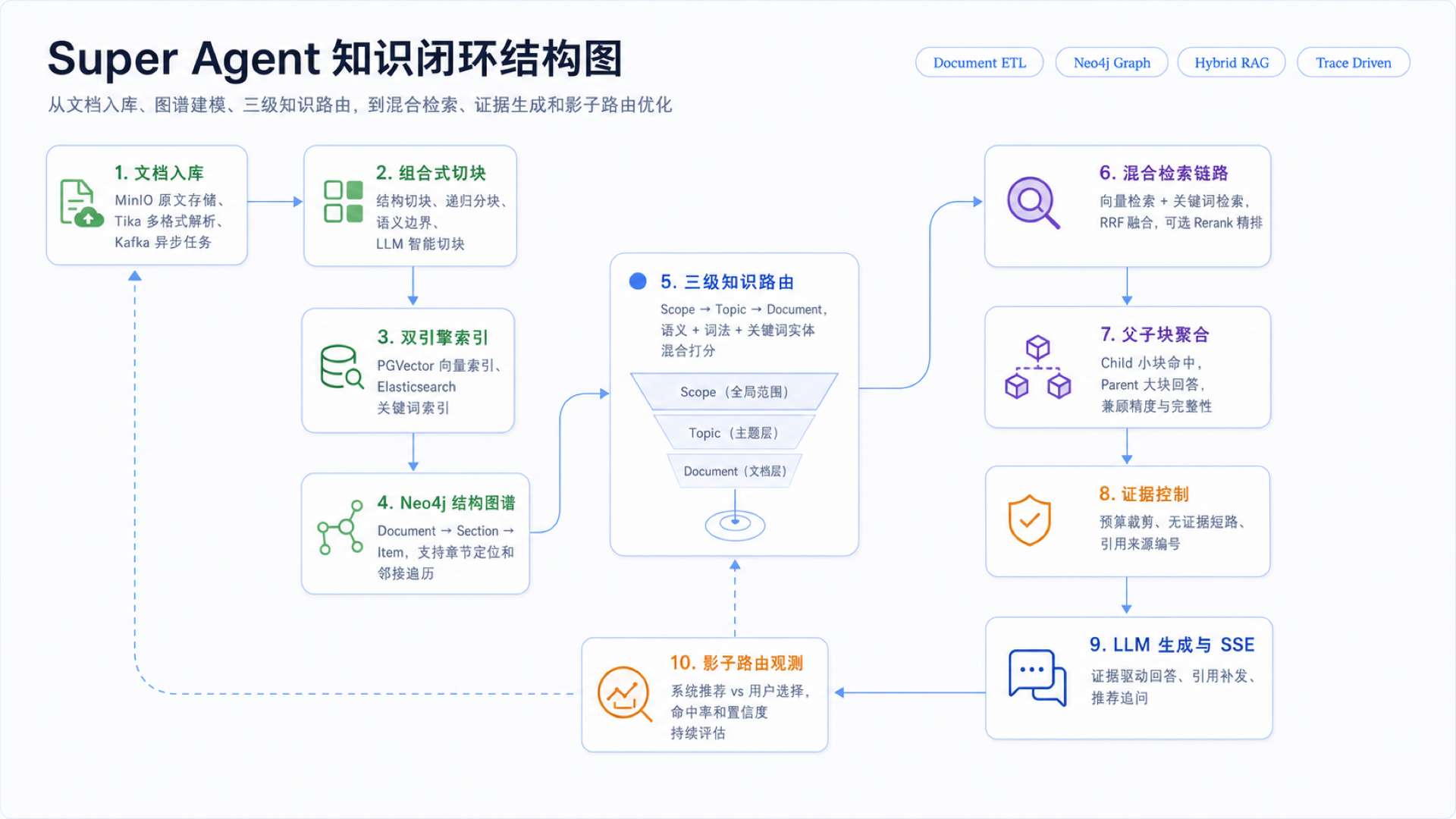
这条闭环里,前半段负责把原始文档加工成可检索、可导航、可路由的知识资产;中间通过 Scope → Topic → Document 三级漏斗缩小检索范围;后半段通过向量检索、关键词检索、父子块聚合和证据控制生成可靠回答。最后,影子路由会把系统推荐结果和用户实际选择记录下来,持续反哺知识路由质量评估。
为什么需要图数据库
先说一个实际场景。用户问:"第三章第二节讲了什么?"
这种问题,向量检索和关键词检索都很难处理——"第三章第二节"不是一个语义概念,也不是一个关键词,它是一个结构定位。你需要知道文档的目录结构,才能找到对应的内容。
再比如用户问:"上一节讲的是什么?"这是一个邻接查询,需要知道当前节点的前一个兄弟节点是谁。
这些场景用关系型数据库也能做,但会非常的别扭。你得写一堆递归查询来遍历树结构。而图数据库天生就是干这个的,节点和关系就是它的一等公民。
Neo4j 是图数据库领域的事实标准,Cypher 查询语言对图遍历的表达力远超 SQL。在 Super Agent 的场景中,文档结构天然就是一棵树(Document → Section → Item),用图来存储和查询是最自然的选择。而且 Neo4j 的 Java Driver 和 Spring 生态集成得很好,接入成本低。
Neo4j 中的文档结构图谱
每份文档在完成索引构建后,系统会同步在 Neo4j 中生成一张结构图谱:

三种节点类型
| 节点类型 | 说明 | 关键属性 |
|---|---|---|
| Document | 文档根节点,一份文档对应一个 | documentId、title |
| Section | 章节节点,对应文档中的标题层级 | nodeCode(如 "1.2.3")、title、normalizedPath、canonicalPath、contentText |
| Item | 条目节点,对应步骤、列表项等细粒度内容 | anchorText、contentText |
支持的图查询能力
有了这张图,系统就能做到很多向量检索做不到的事情:
- 章节编号定位:用户问"1.2.3 节讲了什么",直接通过
nodeCode精准定位,不需要语义匹配 - 标题路径查找:用户提到"考勤制度下面的请假流程",沿着
normalizedPath就能找到 - 邻接遍历:用户问"上一节 / 下一节是什么",通过
NEXT_SIBLING关系直接跳转 - 子节点展开:用户问"这一章有哪些内容",展开
HAS_CHILD关系就能拿到完整目录 - 最佳匹配:给定一个主题和关键词,在图中找到语义最接近的章节
图查询擅长处理结构性问题("第几章""上一节""目录"),向量检索擅长处理语义性问题("怎么请假""墨盒怎么换")。Super Agent 的 DocumentQuestionRouter 会先分析问题类型,结构性问题走图查询(GRAPH_ONLY 或 GRAPH_THEN_EVIDENCE 模式),语义性问题走混合检索(RETRIEVAL 模式)。两条路径各司其职,不是非此即彼。
知识路由:三级漏斗自动选文档
图数据库解决了"文档内部怎么导航"的问题。但还有一个更前置的问题:用户提了一个问题,系统怎么知道应该去哪份文档里找答案?
这就是知识路由要干的事。
想象一下你去图书馆找资料。你不会把所有书架都翻一遍,而是先确定"我要找的是哪个学科的"(Scope),再确定"具体是哪个主题"(Topic),最后才锁定"应该看哪本书"(Document)。知识路由的思路完全一样——三级漏斗,逐层收窄。

第一级:Scope 排序 — 锁定知识域
Scope 可以理解为"知识域"或者"学科分类"。比如一个企业的知识库可能有这些 Scope:HR 制度、产品手册、开发文档、运维手册。
系统拿到用户问题后,先对所有 Scope 节点做一轮排序。排序不是只看语义相似度,而是语义打分 + 词法打分双管齐下:
- 语义打分:把用户问题和 Scope 的描述文本都做 Embedding,算余弦相似度
- 词法打分:用 ES 做关键词匹配,捕捉语义模型可能漏掉的精确匹配信号
两个分数加权融合后,取 Top 5 作为候选 Scope。
第二级:Topic 排序 — 锁定主题
在候选 Scope 的范围内,进一步细化到具体主题。比如 HR 制度这个 Scope 下面可能有:考勤与假期、薪酬福利、晋升制度等 Topic。
这一级的打分维度更丰富:
- 语义打分:和 Scope 排序一样
- 词法打分:和 Scope 排序一样
- 关键词实体匹配:从用户问题中提取关键词实体,和 Topic 的路由文本做匹配
- Scope 归属加分:如果 Topic 属于排名第一的 Scope,额外加 8 分
取 Top 8 作为候选 Topic。
第三级:Document 排序 — 锁定文档
最后一级,在候选 Topic 关联的文档范围内,找到最匹配的文档。这一级的打分最复杂,因为要综合考虑多个信号:
| 打分维度 | 说明 | 权重 |
|---|---|---|
| 语义相似度 | 问题与文档 Profile 的 Embedding 相似度 | 主分 |
| 词法匹配 | ES 关键词匹配分数 | 辅助分 |
| 关键词实体 | 问题关键词与文档路由文本的匹配度 | 辅助分 |
| Scope 匹配加分 | 文档所属 Scope 与 Top Scope 一致 | +15 |
| Topic 关联加分 | 文档与候选 Topic 的关联强度 | ×20 |
Topic-Document 关联分数乘以 20,看起来权重很大。这是因为 Topic 和 Document 之间的关联是在知识库构建阶段就预先计算好的,质量很高。如果一份文档和某个 Topic 强关联,而这个 Topic 又是用户问题的最佳匹配,那这份文档大概率就是正确答案。这个加分相当于把"领域专家的判断"注入到了路由决策中。
置信度评估
排序完成后,系统不是无脑取第一名就完事了,还要评估路由结果的可信度:
confidence = topScore / max(10, topScore + secondScore + 5)
这个公式的含义是:第一名的分数占总分的比例越高,置信度越高。如果第一名和第二名分数很接近,说明系统也拿不准,置信度就会低。
根据置信度,路由结果分三种状态:
- SUCCESS(置信度 ≥ 0.55):系统很确定应该去这份文档找答案
- LOW_CONFIDENCE(0 < 置信度 < 0.55):系统不太确定,但还是用排名最高的文档,同时标记为低置信度
- FAILED(无候选):完全找不到匹配的文档
你可能会想,为什么不直接设一个分数阈值,低于阈值就不路由?因为分数的绝对值受很多因素影响(Embedding 模型、文档数量、文本长度等),不同知识库之间没有可比性。而置信度看的是相对差距——第一名比第二名领先多少,这个指标更稳定,也更有实际意义。
影子路由:不打扰用户的质量观测
知识路由做好了,怎么知道它到底准不准?
最直接的办法是上线后看用户反馈,但这太被动了。Super Agent 设计了一个更聪明的方案——影子路由。
什么是影子路由
影子路由的核心思路很简单:当用户手动选择了一份文档进行问答时,系统在后台悄悄跑一遍完整的知识路由算法,看看系统自己会选哪份文档,然后和用户的实际选择做对比。
整个过程对用户完全透明,不影响任何交互体验,所以叫"影子"路由。

影子路由记录了什么
每次影子路由执行后,系统会把完整的决策过程保存到数据库中,记录的信息非常详细:
| 记录字段 | 说明 |
|---|---|
| 原始问题 + 改写后问题 | 路由用的是改写后的问题,方便对比改写效果 |
| Top 3 Scope 候选 | 第一级排序的前三名,含分数 |
| Top 3 Topic 候选 | 第二级排序的前三名,含分数 |
| Top 3 Document 候选 | 第三级排序的前三名,含分数 |
| 用户实际选择的文档 ID | 用户手动选的是哪份文档 |
| 是否命中 | 系统推荐的第一名和用户选择是否一致(1/0) |
| 置信度 | 路由的置信度分数 |
| 路由状态 | SUCCESS / LOW_CONFIDENCE / FAILED |
影子路由的价值
这些数据积累下来,能回答很多关键问题:
- 路由准确率是多少? 统计
hitSelectedDocument = 1的比例,就是路由的命中率 - 哪些场景路由容易出错? 筛选
hitSelectedDocument = 0的记录,分析失败 case 的共性 - 置信度阈值设得合不合理? 看 LOW_CONFIDENCE 状态下的实际命中率,如果命中率还不错,说明阈值可以适当降低
- Scope / Topic 的划分合不合理? 如果某个 Scope 下的路由命中率明显低于其他 Scope,可能需要调整知识域的划分
影子路由本质上是在做一种特殊的 A/B 测试:A 组是用户的真实选择(ground truth),B 组是系统的自动路由结果。通过持续对比两组数据,可以量化路由模型的质量,并且有针对性地优化。这种"不打扰用户、持续收集反馈"的设计思路,在生产级 AI 系统中非常实用。
知识路由和检索链路是怎么串起来的
最后把知识路由放回到整体链路中,看看它在系统中的位置:

简单来说:
- DOCUMENT 模式(用户手动选了文档):直接用用户选的文档,同时后台跑影子路由做质量观测
- AUTO_DOCUMENT 模式(系统自动选文档):走知识路由三级漏斗,自动锁定文档,记录路由 Trace
- 锁定文档后,进入
DocumentQuestionRouter,根据问题类型决定走图查询还是混合检索 - 最后执行检索和证据驱动生成
知识路由解决的是"去哪找"的问题,文档问题路由解决的是"怎么找"的问题,检索引擎解决的是"找什么"的问题。 三者各司其职,层层递进。
下面这张截图是观测面板中"这轮回答的关键结果"视图。可以看到一次完整对话的核心决策链路:前置编排的诊断结果、检索执行情况、预处理阶段的各项判定,以及最终的执行路径(比如 GRAPH_THEN_EVIDENCE 表示先走图查询再补充证据检索)。这些信息把知识路由、文档问题路由、检索引擎三者的协作过程完整呈现了出来:

面试中怎么聊这块
如果面试官问到知识路由相关的话题,可以从这几个角度展开:
Q:你们的 RAG 系统是怎么处理多文档场景的?
A:我们设计了一套知识路由机制,在进入检索链路之前,先通过三级漏斗(Scope → Topic → Document)自动锁定最相关的文档。每一级都用语义 + 词法的混合打分,最后通过置信度评估来判断路由结果是否可靠。置信度不够的时候会主动降级,不会硬猜。
Q:怎么评估路由效果?
A:我们做了影子路由机制。当用户手动选择文档时,系统在后台静默跑一遍完整路由,对比系统推荐和用户实际选择是否一致,把命中率、置信度、候选排名全部记录下来。这样就能持续量化路由质量,有针对性地优化。
Q:为什么用图数据库?
A:文档内部有天然的层级结构(章节、段落、条目),用户经常会问结构性问题,比如"第三章讲了什么""上一节是什么"。这类问题向量检索处理不了,但图数据库天生擅长。我们在 Neo4j 中构建了 Document → Section → Item 的结构图谱,支持章节定位、邻接遍历、子节点展开等图查询,和向量检索形成互补。